

One of the most central aspects of language learning is the learning of words. Casual observation tells us that a learner with a knowledge of the relevant words can get a message across to native speakers, even without much grasp of grammatical structure above word level, whereas for somebody with the opposite distribution of language skills, this will typically not work out.
Learners can be beginners, intermediate or advanced in their studies of a language. When creating exercises for language learners, it is important to know their proficiency level, in order to tailor the difficulty of words they will be confronted with accordingly. If a learner is consistently presented with words they cannot be expected to understand at their current level, this leads to frustration. On the other hand, if a learner is consistently presented with words that are deemed easy for their current level, this leads to boredom. The art consists in finding words that are challenging enough but not too challenging.
Consequently, in developing algorithms for automatic construction of exercises for language learners, being able to determine word difficulty automatically becomes a central goal. This seemingly simple statement has hidden depths, however.
In my research, I am investigating word difficulty. But what is word difficulty and how can it be measured? First of all, there are many aspects to difficulty, such as phonological difficulty (the word contains sounds that are difficult for the learner), graphematic difficulty (the word might be spelled inconsistently with regard to pronunciation or might be written in a different script), semantic difficulty (the word might have different senses, some of which might be harder to acquire), among others. I am specifically looking at how to operationalize what is commonly referred to as lexical difficulty, or lexical complexity, of single words (deferring the treatment of multi-word expressions for future research). Among the many factors that go into the calculation and prediction of lexical difficulty are word length, number of syllables, number of senses, and topic information.
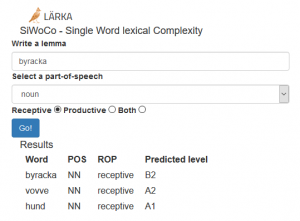
We have integrated the current results of this work in our language learning platform Lärka, a platform that generates exercises for learners of Swedish as a second language. There is a module which uses machine learning to predict the difficulty of single words, SiWoCo (Single Word Complexity).
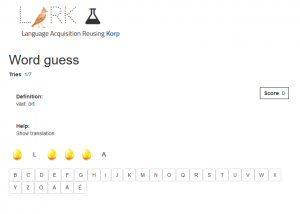
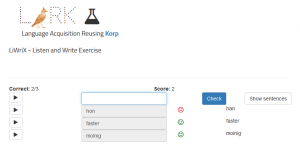
Information about word difficulty is also used in language learning exercises such as WordGuess, a hangman-type game where learners have to guess a word based on its definition, and LiWriX, a dictation exercise where learners hear a word and have to type it out.
In conclusion, calculating single word lexical complexity and being able to predict the difficulty of words greatly benefits language learners. A point that must be made is that words that have more than one sense (such as the word mouse, denoting both the animal and the computer equipment) will be attributed only one difficulty level, instead of possibly assigning different difficulty levels to the different senses. We are currently working on sense-based lexical complexity to address this issue.