

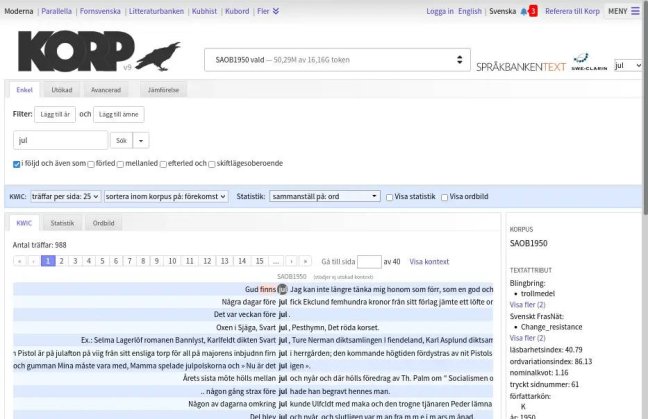
SAOB1950 är en korpus bestående av inscannade böcker från 1950 till 2007. Texterna används som källmaterial för att uppdatera SAOB, Svenska Akademiens ordbok, med ett urval som speglar det svenska ordförrådet framför allt under 1900-talets senare hälft.
Nu finns korpusen i Korp, både i det moderna läget, och i ett eget SAOB-läge där SAOB-redaktionen gjort ett eget korpusurval.
Korpusen finns även att ladda ner som omkastade meningsmängder från Språkbanken Texts sida med språkliga data.
Ordlista
- korpus: en stor samling språkliga data


