Our first concern was to make the results of the alignment immediately available to others. In that context, the most expeditious alternative was to use a relational database. That gave us the possibility of postponing a decision concerning how the text should be annotated and at the same time provided a simple mechanism for searching and retrieving data in the form of parallel concordances. The structure of the database is such that we are still able to generate documents with standard annotations, such as TEI markup, with a minimum of effort. More will be said about this when we turn our attention to annotation below.
The simplest structure, aligning Swedish with another (single) language will be described first.
We began by keeping two tables--for the sake of illustration, one for Swedish and one for English--of unique graphical words that occur in our texts. Each table is then related to another table containing the occurences of each word for the respective languages. The latter tables contain fields for the domain of the text that particular occurence of a word is found in, and administrative fields relating the occurences to text identifiers and sentence identifiers within each text. Separate tables are kept for sentences. These tables contain, besides the sentences themselves, the necessary information to identify them with a text type or domain, a unique text and their position within that text as is illustrated in figure 1.

Figure 1: This is a partial view of the table containing the English
sentences and some of the related data.
The user is able to search on whole words or parts of words. Thus it is possible to search for all Swedish words ending in ``*ande'' or ``*ende'' to find all occurences of forms built like the the present participle or to search for the first or last component of compound words such as ``för*'' or ``*lägga''. The results are presented in a window with the search word and two text boxes, one for the source language and one for the target language. The word that was searched upon is highlighted in the relevant text box. This is illustrated in figure 2.
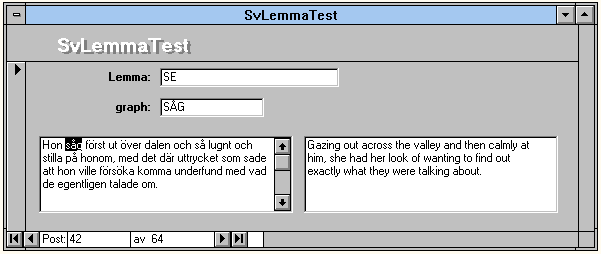
Figure 2: This is what the user is presented with after searching for
the lemma ``se.''
The next step was to add a full-form lexicon for Swedish. No attempt has been made to separate homographs. A search for the verb ``ta'' (take) will return occurences of ``tag'' (imperative) as well as ``tag'' as in ``praktiskt taget''. Nothing is lost, since a search on the lemma ``tag'' (praktiskt taget) will return the correct forms as well as a few forms of the imperative of ``ta''. We have no immediate plans to do anything about this. Our position is that in these cases the results are going to be evaluated by a human being who will easily weed out the erroneous search results. A fragment of the table can be seen in figure 3.
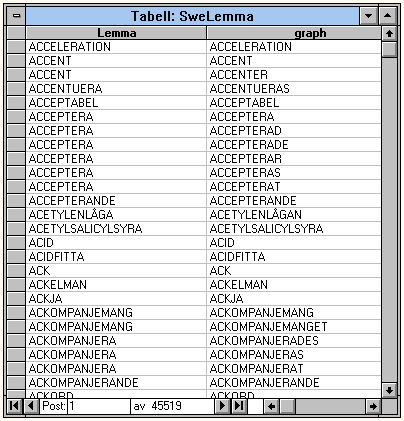
Figure 3: A fragment of the table containing the full forms used when
searching on lemmas.