

We at Språkbanken Text have just released a new corpus of native (L1) and non-native (L2) speech in four languages: English, Spanish, French and Italian. The corpus contains more than 170 million words produced by more than 97 thousand speakers (size varies a lot across the four languages, though).
The corpus has been created by scraping WordReference forums, where users discuss various questions about languages. Importantly, every user has to provide their native language, and this information, alongside with the nickname, is publicly available (and, of course, visible to other users). Furthermore, for English, French, Italian and Spanish there exist forums “English Only”, “Français Seulement”, “Solo Italiano” and “Sólo Español”, where all communication should occur only in the respective language, and this rule is generally observed.
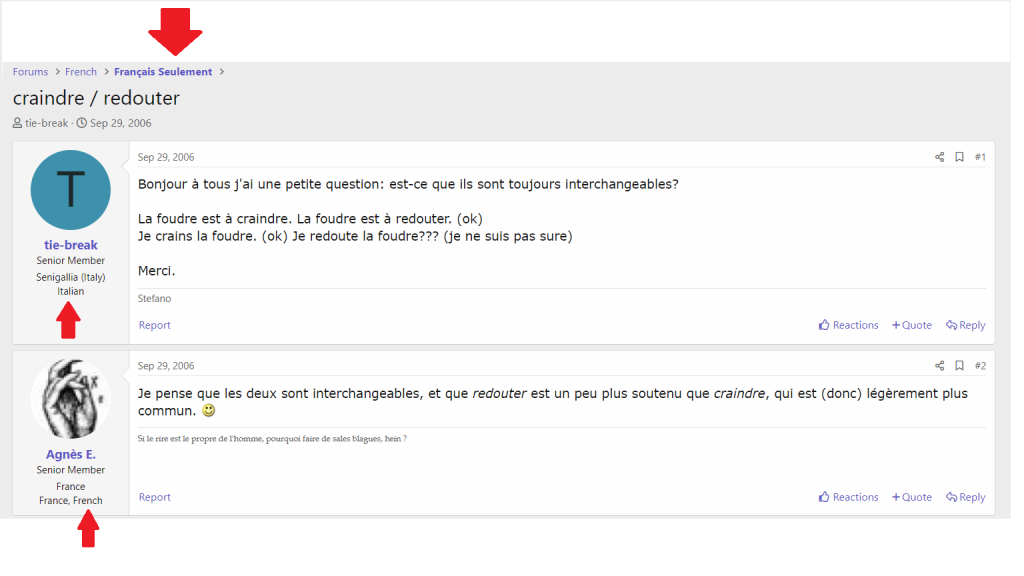
The corpus has several important advantages: it's open-access, large and contains completely natural written production. Moreover, it contains comparable production of L1 and L2 speakers. Finally, at least for some messages it can be automatically inferred to whom they are addressed, thus providing information about the dialogue structure. In the example above, for instance, we can be sure that communication occurs in French, and that Agnès E., an L1 speaker, is addressing tie-break, an L2 speaker.
There are, of course, certain limitations: most texts in the corpus are very short; there is no explicit information about how proficient the L2 speakers actually are; there is currently no annotation (part-of-speech, lemmatization, syntax etc.). Technically, adding the annotation is easy, but there is a risk that it will contain some systematic bias (e.g. have lower quality on L2 data), which might skew future research results. Establishing whether such bias exists and if yes, how to get rid of it, is a non-trivial task.
Nonetheless, even in its current form the corpus can be used for various research purposes. In this paper, for instance, I show that when L1 speakers address L2 speakers, their production is significantly simpler than when they write to other L1s. This phenomenon ("foreigner-directed speech") has long been claimed to exist, but as far as I know, until now, it has never been observed in a large-scale corpus study. Meanwhile, the existence and pervasiveness of foreigner-directed speech may have far-reaching consequences for some theories about language change.