

(This blog is based on a joint research and publication in collaboration with David Alfter, Therese Lindström Tiedemann, Maisa Lauriala and Daniela Piipponen)
At our department, and outside, we are used to search Korp corpora using the linguistic categories available there. Some of us know that these linguistic categories come as a result of automatic annotation by the Sparv-pipeline. The pipeline automatically splits raw text into tokens, sentences, finds a base form to each of the running (inflected) words, assigns word classes, syntactic relations and more. Sparv pipeline (Borin et al., 2016) relies on annotation standards from the Stockholm Umeå Corpus (SUC) (Ejerhed et al.,1997; Gustafson-Capková and Hartmann, 2006) and on the theoretical framework in the Saldo lexicon (Borin et al., 2013). We tend to use these annotations in our research for generalizations about the language. The question is, however, to which degree such conclusions and generalizations are correct?
Recently, a group of researchers and assistants from the project “Development of lexical and grammatical competences in immigrant Swedish” (in short, L2P) carried out a small check on the quality of Sparv annotation. We looked into multi-word detection, word sense disambiguation, lemmatization and a number of other linguistic parameters. In this blog I will describe the results for the word sense disambiguation (WSD) check, which is a process of automatically assigning one of possible senses to a text word. Sparv pipeline uses senses available in Saldo lexicon, the WSD algorithm being a recent addition to the pipeline (Nieto Piña, 2019).
We evaluated to which degree the current Sparv-pipeline for Swedish can handle the identification of correct lemgrams and the assignment of correct senses in three different contexts: native speaker writings (L1), original second language writings/essays (L2-orig) and corrected L2 essays (L2-norm). We explored three main hypotheses:
1. Pipelines trained on a standard language (i.e. native language, L1) do not perform similarly well on non-standard languages such as non-native, second language (L2).
2. Standardization of non-standard languages (in our case L2), for example through error correction, improves tool performance.
3. The need for standardization is especially critical for L2 texts written by learners of lower levels of proficiency since they are likely to contain a higher level of misspellings, wrong words and syntactic discrepancies in comparison to the standard.
Even though some of the claims above appeal to common sense, they need to be explicitly confirmed.
On a subset of 15 texts per each of the three text types (L1, L2-orig and L2-norm), with three texts per level of proficiency (from low levels and up: A1, A2, B1, B2, C1), two linguistically trained assistants manually analyzed the automatic tags, introducing corrections where necessary according to guidelines. The goal with this check was to find out whether, for each token:
1. the sense was correctly identified
2. no sense was assigned at all
3. the lemgram or lemma for the correct sense was missing in Saldo
4. the correct sense was missing in Saldo
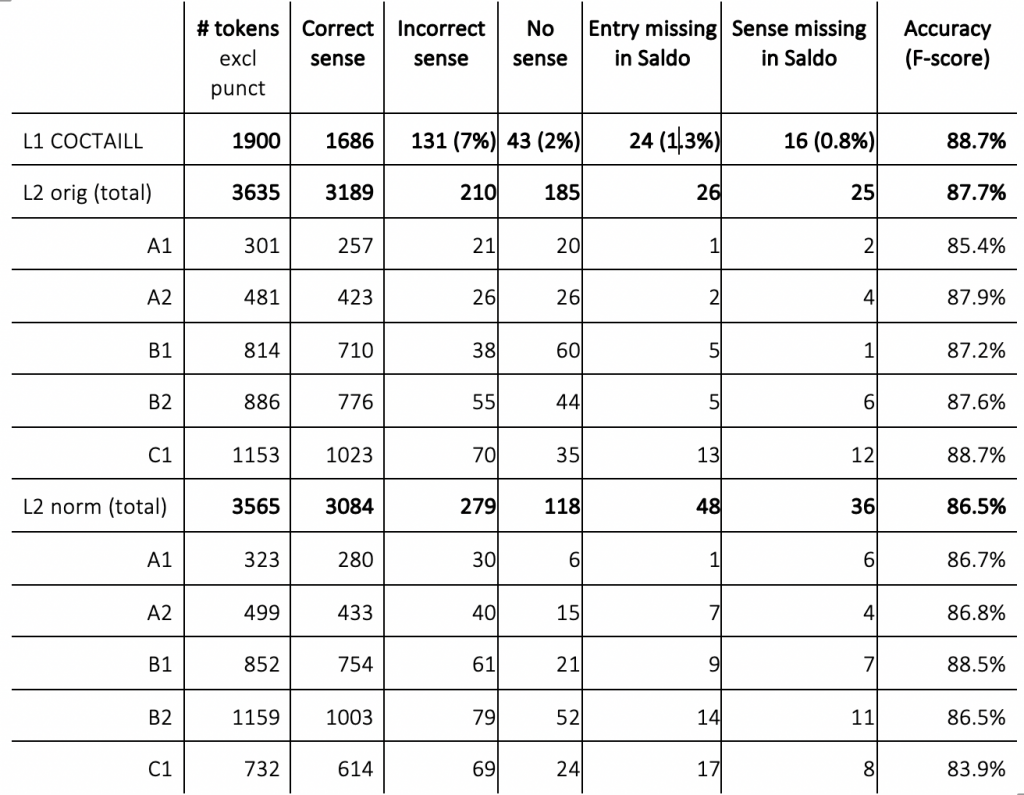
The results of the evaluation are very encouraging (see the Table). We can see that in the three datasets, the accuracy of sense disambiguation is high, with very slight fluctuations between the datasets. Counter to our expectations, we do not see any radical improvement in performance following normalization of L2 errors in essays, nor is there any distinct tendency for poorer sense disambiguation quality on the lower levels of proficiency. On inspection, we could see that some senses are missing in Saldo; sometimes even lemgrams are missing. Most challenging are function words, like som, mången, än (Eng. as, much, yet), that have very few (sense-based) entries in Saldo, and often in combination with a part of speech (POS) that does not match POS-tagging based on SUC, which then leads to mismatches and failure on the word sense disambiguation task. Checking the quality of automatic word sense disambiguation on a small subset of our data has shown that we can expect correct sense in 8-9 cases out of 10. Despite the fact that the word sense disambiguation in Sparv is not bullet-proof, we consider it reliable enough to base theoretical conclusions in our studies.
=========
Our experiment complements and extends the report by Ljunglöf et al. (2019) who looked into the Sparv pipeline from the point of view of automatic tools, models and modules rather than the reliability of annotations. Evaluation of other linguistic aspects annotated by Sparv (multi-word expression detection, tokenization, lemmatization, POS-tagging, etc) will be targeted in the coming blogs.
=========
- Borin, L., Forsberg, M., Hammarstedt, M., Rosén, D., Schäfer, R., and Schumacher, A. (2016). Sparv: Språkbanken’s corpus annotation pipeline infrastructure. In The Sixth Swedish Language TechnologyConference (SLTC), Umeå University, pages 17–18.
- Borin, L., Forsberg, M., and Lönngren, L. (2013). SALDO: a touch of yin to WordNet’s yang. Language Resources and Evaluation, 47(4): 1191–1211
- Ejerhed, E., Källgren, G., and Brodda, B. (1997). Stockholm umeå corpus version 1.0, suc 1.0.De-partment of Linguistics, Umeå University
- Gustafson-Capková, S. and Hartmann, B. (2006). Manual of the Stockholm Umeå Corpus version 2.0. Unpublished Work
- Ljunglöf, P., Zechner, N., Nieto Piña, L., Adesam, Y., and Borin, L. (2019). Assessing the quality of Språkbanken’s annotations.
- Nieto Piña, L. (2019). Splitting rocks: Learning word sense representations from corpora and lexica. PhDThesis, Data Linguistica 30.