

Språkbanken Text develops a language technology infrastruture by making language data freely available and by providing open platforms for exploring them. You can download our data but also explore them using our platforms, described below.
Based on the conviction that openness should permeate all research and support review and collaboration, we strive to use open standards and create software that is free and open-source. Most of our software is available on GitHub. Read more about our API:s. You can find our published Python packages on PyPI.
If you have any questions regarding our platforms, please contact us. If you use our platforms, please cite us.


Korp is Språkbanken Text's word research platform for querying large amounts of text from newspapers, fiction, social media and other genres.


Karp is Språkbanken Text's data editing platform where you can edit structured data, such as dictionaries. Karp allows searches based on word forms, inflections, and complex queries involving multiple criteria. In Karp, you will find several dictionaries, primarily in Swedish."


Strix is Språkbanken Text's text research platform where you can explore large amounts of language-technologically refined texts at the document level. With Strix, you can search a wide collection of corpora, generate statistics, and explore similar documents through vector search.

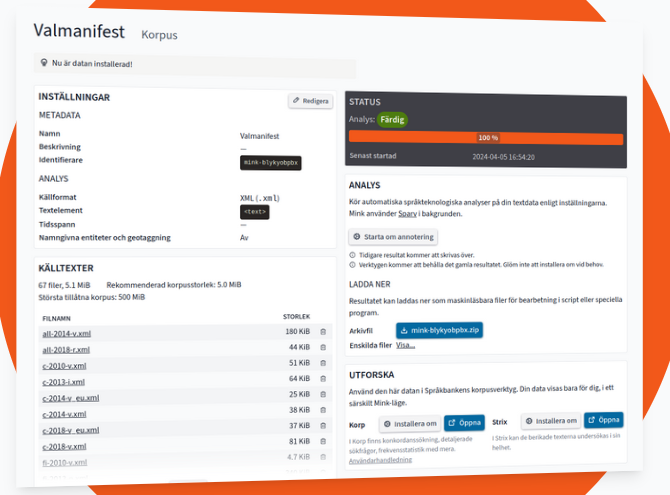
Mink is Språkbanken Text's data platform where you can use our analyses and platforms for data resources that you create yourself.


Sparv is Språkbanken Text’s analysis platform – a powerful command line tool designed for annotating text with a wide range of linguistic annotations. Our corpora are mostly annotated by Sparv.


Lärka is Språkbanken Text's learning platform designed for learning Swedish based on principles of Intelligent Computer-Assisted Language Learning. Lärka is currently not under development and certain parts may have stopped functioning.
Development versions and prototypes
In case you cannot find what you are looking for, or if you are interested in more of our software, try the Development versions and prototypes page or the Resources catalog.