

Hi!
Our names are Ebba and Anastasia.
We are fourteen years old and go to Montessoriskolan Kvarnhjulet in 8th grade. Over the past three days we have had a chance to do an internship (=PRAO) at Gothenburg university with a researcher from Språkbanken, Elena Volodina, who is working on automatic support for Swedish as a second language. During these three days we have been doing many different things, but the first day was more of an introduction to what we were going to be working with.
When we first got here, we were given a tour around the university. We got to see classrooms, different rooms for group projects, lunchrooms and many other things that were pretty different from what our school looks like. It was very interesting to get to see everything as all of it was new to us. We then got an introduction to some of the things that they are working with at Språkbanken.
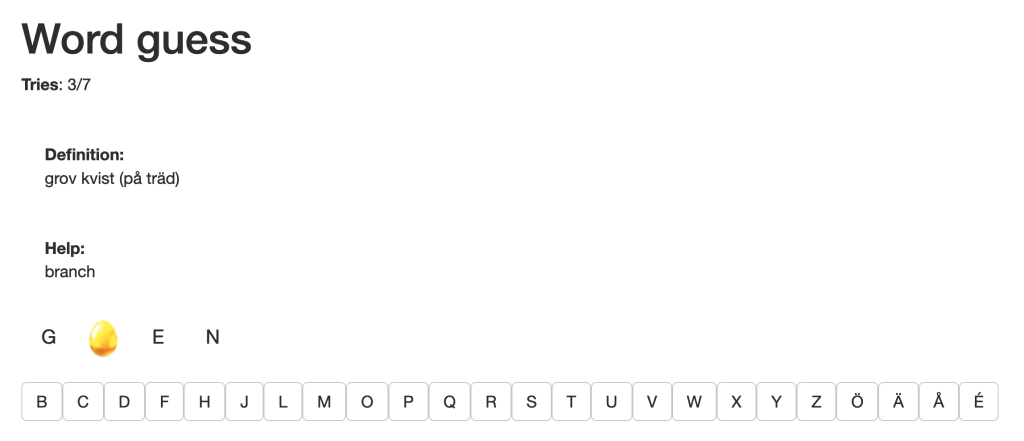
The first thing we were working with was exercise generators for language studies, such as WordGuess, Bundles Gaps, etc. In WordGuess (Alfter et al., 2019) we got to guess Swedish words by a definition of that word with other Swedish words. We thought this exercise was good, because it was fun for us to work with, at the same time being a great and effective way to learn new Swedish words for people learning Swedish as a second language. In most cases, we understood what word the definition was referring to, but we also noticed that some descriptions were significantly harder to understand than others, even though they were on the same level of difficulty. This exercise reminded us of a Hangman game that we love to play.
Another exercise we worked on was aimed at Particle verbs (Alfter and Graën, 2019). It was a bit harder than the previous exercise because we were unfamiliar with particle verbs as we haven't been working with them before at school.
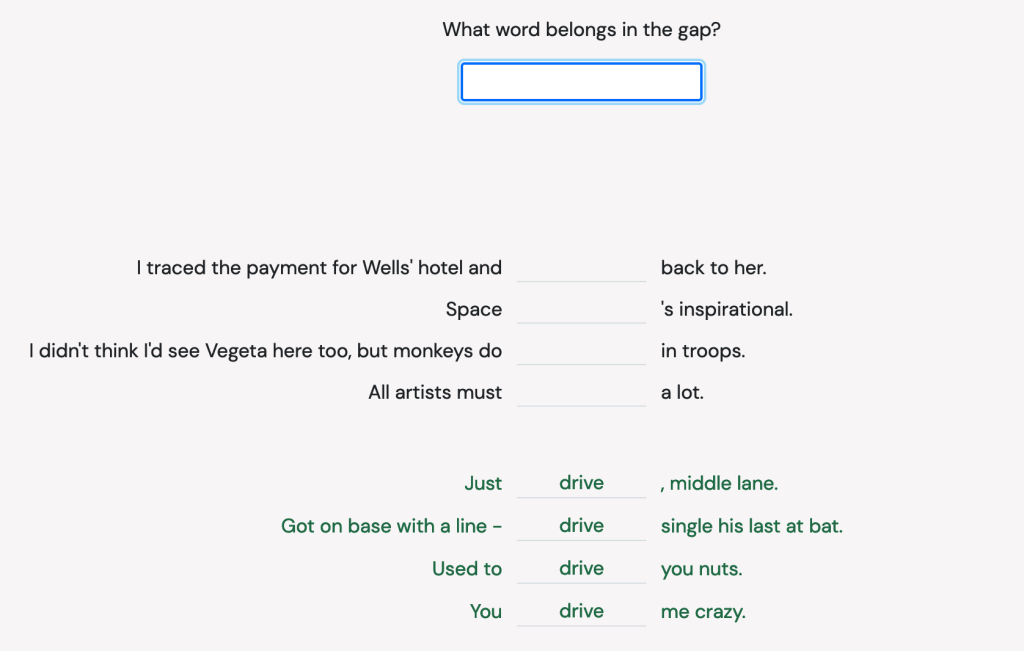
An exercise that we found interesting was Bundled Gaps (Wojatzki et al., 2016; Thelitz and Säuberli, 2021) for English. In this exercise, there are four sentences with a gap in each of them. All of these gaps are supposed to be filled with the same word in the same form, and you are supposed to guess this word judging by the use of the context of each sentence. This was more of a challenging task for us, which also made it fun to work with.
Later, we were shown a program called ‘VIEW’ (Meurers et al., 2010), which is a web add-on that can take a text from the internet and generate exercises right from the text. In this program, you can choose many different functions and ways to do the exercises, which is great as different people like to learn new things in different ways. You can also choose different languages and word classes to work with in this program, which makes it even more suitable for many people. We actually find this function so great that we think that it could be used in schools as an exercise for learning word classes in an entertaining and effective way. Too bad there is no Swedish on the offer, though.
The last exercise that we got to do was evaluating translations between Swedish and English sentences, as a kind of “cleaning” of automatically linked sentence pairs. For that, we used a program PaCLE developed by Johannes Gräen for use by a “crowd” (as a crowdsourcing task), where you are supposed to read translations from Swedish to English and check whether they are translated correctly or not, to help collect data for new exercises for learning Swedish as a second language.
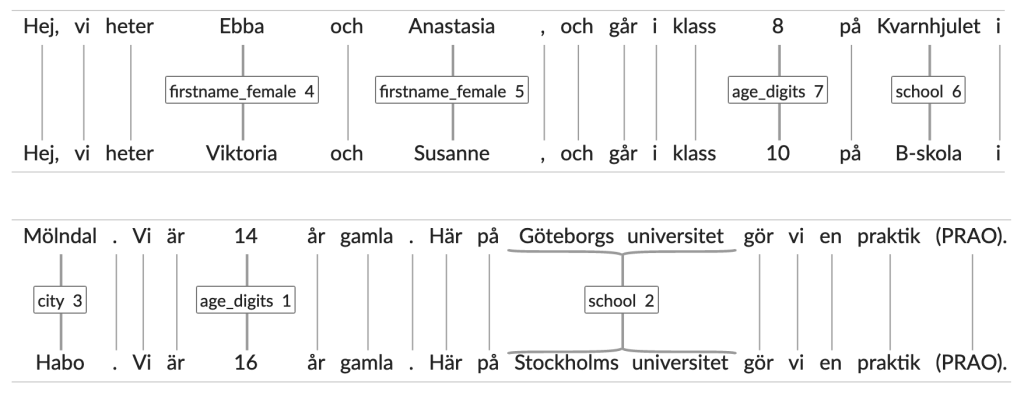
After this introduction, our main task was to create an “evaluation dataset for pseudonymization for English”. To understand what pseudonymization is for something, we got to see how some personal information about us was automatically replaced by a tool developed at Språkbaken (see a picture below) (Volodina et al., 2020). We were very impressed, and got motivated to help with a similar tool for English.
In our main task, we had to translate Swedish texts written by people who have Swedish as their second language into English. While doing this we were also supposed to keep their misspellings as far as we could. This was both a challenging task and a very fun one, as it sometimes was hard to translate the sentences. Some original misspellings were difficult not to smile at, and especially when translating them into English. For example, when someone wrote “manningkor” instead of “människor”, we translated it to “poople” (instead of people) and then laughed at it for a very long time. We hope that our translations will be of use to researchers working on the pseudonymization program and look forward to using it one day.
Apart from the very interesting work tasks, two things that we really liked and enjoyed about the University of Gothenburg are the many places for work and the food. We think that the food here was excellent, as it was tasty at the same time as it was healthy and nutritious. After eating the food from the restaurant here, our energy level stayed balanced and we didn’t get hungry for a very long time. This also helped us to concentrate better when working afterwards.

We enjoyed the possibility of changing places to sit down and work at. During our visit here, we sat at many different places, including the big stairs, some small tables that can spin beside a big window, on a sofa and in some armchairs. At each of these places, we felt motivated to work. We think that this is thanks to the calm environment and closeness to nature, which was something that you could see through some of the big windows and glass walls that they have here.
During our visit here, we also got to meet some of Elena’s colleagues, as well as a PhD-student and a master student who came for a supervision meeting.
In summary, we think that it was great to do an internship here at the University of Gothenburg. It was something beyond the usual things for us and we learned a lot of new things about language learning that we will take with us to the future and won't forget.
We believe that the work that Språkbanken does with regards to Swedish as a second language is very important for society, because it is a great help for whoever wants to learn Swedish as a second language. This helps people who come to Sweden from other countries to learn the language in a more effective way, which in turn leads to easier communication for them with the other people who live here. We are beyond happy that we got to help with such an important task.
We are very thankful that we got the opportunity to do an internship here and we would love to come back here one day.
REFERENCES
David Alfter, Lars Borin, Ildikó Pilán, Therese Lindström Tiedemann, Elena Volodina. 2019. From Language Learning Platform to Infrastructure for Research on Language Learning. CLARIN-2018 post-conference volume. LiUP Press. [pdf]
Alfter David, Graën Johannes (2019), Interconnecting lexical resources and word alignment: How do learners get on with particle verbs?, in Proceedings of the 22nd Nordic Conference on Computational Linguistics, Turku321-326, Linköping University Electronic Press, Linköping321-326. [pdf]
Detmar Meurers, Ramon Ziai, Luiz Amaral, Adriane Boyd, Aleksandar Dimitrov, Vanessa Metcalf, Niels Ott. 2010. Enhancing Authentic Web Pages for Language Learners. Proceedings of the 5th Workshop on Innovative Use of NLP for Building Educational Applications, NAACL-HLT 2010, Los Angeles.
Thilo Thelitz and Andreas Säuberli (2021) Bundled Gaps App. Unpublished course project report, University of Zürich
Wojatzki, Michael, Oren Melamud, and Torsten Zesch. 2016. Bundled gap filling: A new paradigm for unambiguous cloze exercises. In Proceedings of the 11th Workshop on Innovative Use of NLP for Building Educational Applications, pp. 172-181. [pdf]
Elena Volodina, Yousuf Ali Mohammed, Sandra Derbring, Arild Matsson and Beata Megyesi (2020). Towards privacy by design in learner corpora research: A case of on-the-fly pseudonymization of Swedish learner essays. In Proceedings of the 28th International Conference on Computational Linguistics (COLING) (pp. 357-369). [pdf]