

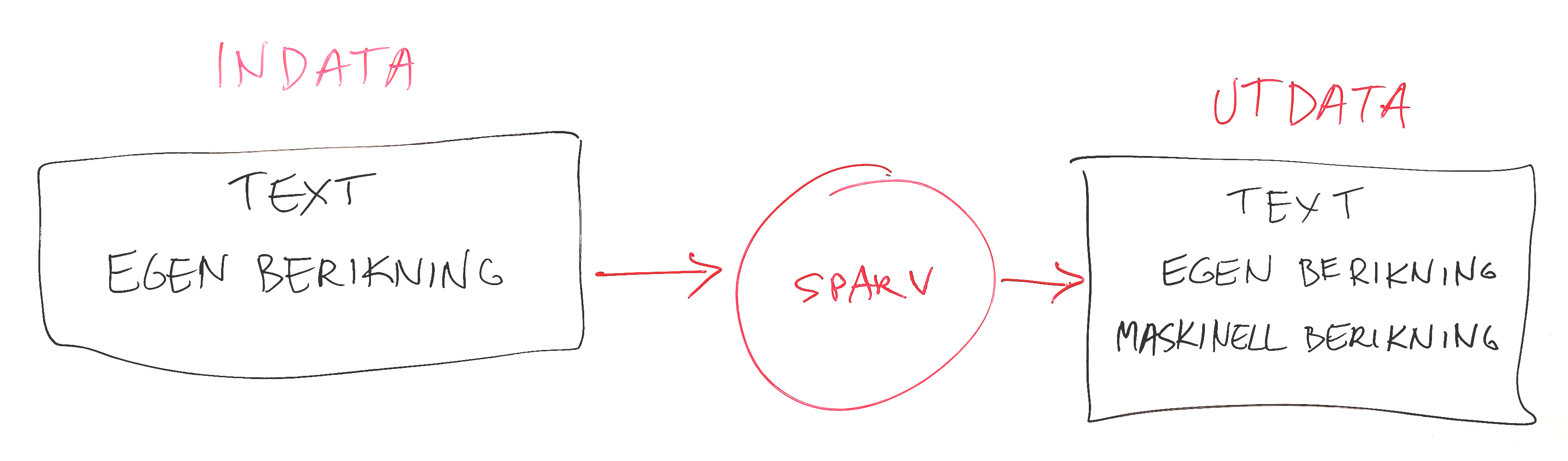
Mink, Språkbankens dataplattform, har en standarduppsättning analyser som körs för att berika din textdata med segmentering och annoteringar.
Du kan också inkludera egen berikning i källtexterna, dvs filerna som du laddar upp som indata till Mink. Det kan till exempel vara:
- metadata såsom datum och författarnamn för texterna
- en specialanpassad tokeniserare som du har kört på materialet
- uppmärkningar från transkription eller annan manuell analys
Enkel segmentering
Det mesta i den här guiden handlar om anpassningar som kan göras om källtexterna är i formatet xml. Oavsett vilket format du använder finns det ändå en inställning för segmentering som kan vara användbar: om texterna är formaterade så att varje mening står på en egen rad, kan du ange detta i inställningen "Existerande meningssegmentering".
Exempel:
Den vilda minken vistas främst i närheten av vattendrag, sjöar och våtmarker
Vintertid lever den huvudsakligen av fisk
På grund av beroendet av vatten för sin jakt har minkar ofta sin lya i en håla nära vattenKälldata i xml
Xml-formatet ger fler möjligheter för egna berikningar än de andra textformaten.
Metadata och egna annotationer på textnivå
När xml används som filformat behöver du ange vilken tagg som markerar en text. I den taggen kan du lägga egna attribut som beskriver texten, dvs metadata eller annotationer på textnivå.
Exempel:
<article
title="Sverige till kvartsfinal"
date="2024-08-12">
Lorem ipsum dolor sit amet
</article>Egna annotationer på flerordsnivå
Taggar och attribut som finns i källfilerna följer automatiskt med till utdatan. Det betyder att du i princip kan göra en egen segmentering och ange annotationer som attribut på segmenttaggarna. På menings- och tokennivå kommer det dock att krocka med Sparvs standardsegmentering. Men det kan vara användbart att göra för att exempelvis märka upp textavsnitt, stycken eller namnentiteter.
Exempel:
<article>
Minkens tidigare vetenskapliga namn var <name type="latin">Mustela vison</name>.
</article>I Korp visas attribut på flerordsnivå, något missvisande, under rubriken Textattribut.
Avancerad konfiguration med konfigurationsfil
För att kontrollera ytterligare hur existerande uppmärkning ska hanteras behövs konfiguration utöver det som stöds av inställningsformuläret. Nederst i formuläret finns knappen "Egen konfiguration" som leder till en sida där du kan ladda upp en egen konfigurationsfil.
Formatet på konfigurationsfilen beskrivs i Sparvs dokumentation. Nedan beskrivs några specifika konfigurationsmöjligheter.
Segmentering
För att ange att en tagg ska tolkas som segmentering, t ex att <ord> betecknar ett token:
xml_import:
elements:
- ord # Registrera egen tagg
classes:
token: ord # Mappa till annotationsklassen `token`Då åsidosätts Sparvs egen tokensegmentering, och det blir <ord>-elementen som används som token i ytterligare analyser.
Annotationer
För att ange att ett attribut, t ex lemma="..." ska tolkas som annotation:
xml_import:
elements:
- ord
- ord:lemma # Registrera eget attribut
classes:
token: ord
token:baseform: <token>:lemma # Mappa till annotationsklassen `token:baseform`Om det finns analyser som använder sig av den symboliska annotationsklassen token:baseform kommer de då att läsa värdena från lemma-attributet.