

What is pseudonymization?
The goal of the Mormor Karl research environment is investigating the methods for and effects of pseudonymization of research data. Privacy-preservation measures such as pseudonymization may not only be legally required but are also worth considering from an ethical standpoint when it comes to sharing language data. While there are many definitions of the concepts of pseudonymization, anonymization, or de-identification, in our case, pseudonymization could be most simply defined as the process in which personal or otherwise sensitive information (PI) is detected and replaced with appropriate placeholders. The appropriateness of the latter may depend on the task or domain (e.g. in a dataset collected to investigate filler words "Maria" may be pseudonymized as "@FirstName," but if the data is to be used in the training of a language model, it may be better to replace this name with "Sara"), and the same is true for the extent to which different types of information should be pseudonymized (e.g. for some uses it may be relevant to preserve the names of medical conditions). This process can be either done in stages (personal information detection + labeling followed by pseudonym generation, see image below) or in one go (e.g. framing it as a seq2seq task or prompting an LLM to perform it, c.f. Yermilov et al. (2023)). This division could of course also apply to how a human annotator may work with the data.
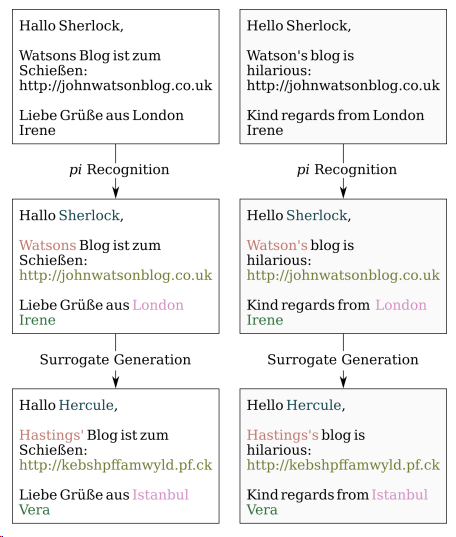
The main focus of Mormor Karl ∩ Språkbanken are automated pseudonymization methods which could be used to assist the manual process — given how high-stakes this process is, assisting a manual process to speed it up is preferable to complete automatization where there is still a chance that personal information may be left unredacted. To this end, we have so far predominantly worked with personal information detection and labeling, e.g. in Szawerna et al. (2024), Szawerna et al. (2025), or Ilinykh & Szawerna (2025). Given how much the Språkbanken research infrastructure may benefit from having access to the models and methods we develop and how beneficial it would be for us to hear from potential end users of pseudonymization assistance tools, this semester I was tasked, as a part of my institution duties, with bringing some of our models over to Sparv — Språkbanken's text annotation pipeline. A great advantage of Sparv is that it can be run locally on the end user's machine, meaning that the data containing potentially personal information does not get uploaded anywhere; additionally, the PI annotation can be done in parallel to other types of annotation (here, obligatorily, sentence splitting and tokenization, but potentially also e.g. NER or POS-tagging). This way PI detection and labeling can already be used in Sparv; hopefully in the future it will be joined by a plugin that allows the user to generate suitable replacements.
Detecting personal information with Sparv
The personal information detection and labeling was brought over to Sparv in the shape of a plugin, which has to be installed once Sparv itself is in place. The plugin, alongside instructions, can be found here, but I will also illustrate how to install it, configure your corpus, and run it below.
The plugin makes use of some of the models that were trained for our experiments in Szawerna et al. (2025). We trained models on data annotated with different levels of granularity: basic, which only differentiated between something being PI or not, general, which made use of a couple of general categories like "name" or "geographic," and specific or detailed, which utilized fine-grained labels like "firstname_female" or "city." All three of these also came in two flavors each: one which distinguished between inside and beginning of a PI span (IOB), and one which did not. Our aim was to see what role the granularity of the classes played in the performance of the models; different models performed best for different tasks (detecting vs. labelling). While the details can be found in the paper itself, the gist of our evaluation can be seen in the table below, where we present the average F2 (defined as (1+22)∗(precision∗recall) /(22∗precision)+recall)) scores and standard deviation for 10-fold cross validation for each setup.
| Model type | F2 (detection) | F2 (labeling) |
| Detailed IOB | 0.724 ± 0.052 | 0.519 ± 0.085 |
| Detailed | 0.756 ± 0.047 | 0.558 ± 0.063 |
| General IOB | 0.770 ± 0.053 | 0.720 ± 0.054 |
| General | 0.813 ± 0.050 | 0.763 ± 0.059 |
| Basic IOB | 0.800 ± 0.045 | 0.800 ± 0.045 |
| Basic | 0.824 ± 0.038 | 0.824 ± 0.038 |
For each setup, one run was picked out and uploaded to Språkbanken Text's HuggingFace, and these are the models available for the plugin. The choice of model is up to the user, and may be motivated by the model's performance or the need for a particular type of annotation. It's important to note here that the models' (and, by extension, the plugin's) effectiveness is limited by the domain of the texts that the user may want to annotate; the current models were trained on learner essays and may be ineffective on medical records. We are, however, planning on updating the models in the future to account for this.
For the plugin itself to work, needs to split its input texts into sentences and tokenizes them. The user can, if they want, specify what to use for those tasks). Subsequently, the text is chunked to comply with the maximum length that these BERT models allow and predictions are obtained. Since BERT-based models annotate on sub-word token level, the model outputs are projected back onto the previously obtained tokens, with the whole token being marked as PI if at least one of its sub-tokens is, and the specific label (for detailed and general models) is determined by the first sub-word token (with the assumption that this is usually the most meaning-bearing segment).
In practice
The plugin itself comes with a mock-corpus, which will here be used to illustrate how to run it. You will have to open a terminal in order to continue with this small tutorial.
Step 0: Install and set up Sparv (if you don't already have it). This can be done from the command line like this (with some choices to make during the setup):
pipx install sparv
sparv setupStep 1: Clone the plugin repository in a directory that you want it to be in:
git clone https://github.com/spraakbanken/sparv-sbx-pi-detectionStep 2: Inject the plugin into Sparv:
pipx inject sparv /YOUR/PATH/TO/THE/PLUGIN/sparv-sbx-pi-detectionThese two steps can be merged into one and the plugin can be injected directly from the repository, but in this case we want to be able to easily find our way to one of the folders in the cloned repository on your machine.
Step 3: Navigate to the testkorpus folder:
cd /YOUR/PATH/TO/THE/PLUGIN/sparv-sbx-pi-detection/sbx_pi_detection/testkorpusStep 4: Investigate the files inside. Inside you can find config.yaml which defines what Sparv should do with the corpus:
metadata:
id: pikorpus # the name for your corpus
language: swe # the language of the corpus, which can affect e.g. tokenization
import:
importer: text_import:parse # the import format is .txt files
text_annotation: text
export:
annotations: # the kinds of annotations the text should receive
- <sentence> # the text will be split into sentences
- <token> # the text will be tokenized
- <token>:sbx_pi_detection.pi # each token will receive a personal information tag
sbx_pi_detection: # the special settings for this plugin
annotation_level: general # the annotation level to be used is "general"You can use this file as a starting point for your own corpus or edit it to include some more annotations for this test corpus, if you want to. The annotation_level setting can take the following values: basic, basic_iob, general, general_iob, detailed, detailed_iob.
Additionally, this directory contains another folder called source. Within it you can find two text files, essay1.txt and essay2.txt. The former one contains an excerpt from my own learner essay from when I started learning Swedish. The latter one you can use to paste or type in your own text!
Step 5: From the directory containing config.yaml run the following command:
sparv runThis will take some time, but after a while the annotation should be done and a new folder, export, should appear. For each .txt file in the source there is now an .xml file with annotation. This way this essay:
Jag heter Maria. Jag kommer från Wroclaw (det är i Polen), men jag bor i Heidelberg. Jag studerar lingvistik på Heidelberg Universitetet. Jag talar polska, engelska och lite tyska. Min pojkvän, Tobias, kommer från Uddevalla, i närheten av Göteborg. Han pratar engelska och svenska såklart. Vi talar engelska med varandra, men jag lär mig svenska och han lär sig polska.
becomes annotated as (by the way, this is not a perfect annotation: see if you can spot where you would disagree with the model!):
<?xml version='1.0' encoding='utf-8'?>
<text>
<sentence>
<token pi="O">Jag</token>
<token pi="O">heter</token>
<token pi="personal_name">Maria</token>
<token pi="O">.</token>
</sentence>
<sentence>
<token pi="O">Jag</token>
<token pi="O">kommer</token>
<token pi="O">från</token>
<token pi="geographic">Wroclaw</token>
<token pi="O">(</token>
<token pi="O">det</token>
<token pi="O">är</token>
<token pi="O">i</token>
<token pi="geographic">Polen</token>
<token pi="O">)</token>
<token pi="O">,</token>
<token pi="O">men</token>
<token pi="O">jag</token>
<token pi="O">bor</token>
<token pi="O">i</token>
<token pi="geographic">Heidelberg</token>
<token pi="O">.</token>
</sentence>
<sentence>
<token pi="O">Jag</token>
<token pi="O">studerar</token>
<token pi="O">lingvistik</token>
<token pi="O">på</token>
<token pi="geographic">Heidelberg</token>
<token pi="O">Universitetet</token>
<token pi="O">.</token>
</sentence>
<sentence>
<token pi="O">Jag</token>
<token pi="O">talar</token>
<token pi="other">polska</token>
<token pi="O">,</token>
<token pi="O">engelska</token>
<token pi="O">och</token>
<token pi="O">lite</token>
<token pi="O">tyska</token>
<token pi="O">.</token>
</sentence>
<sentence>
<token pi="O">Min</token>
<token pi="O">pojkvän</token>
<token pi="O">,</token>
<token pi="personal_name">Tobias</token>
<token pi="O">,</token>
<token pi="O">kommer</token>
<token pi="O">från</token>
<token pi="geographic">Uddevalla</token>
<token pi="O">,</token>
<token pi="O">i</token>
<token pi="O">närheten</token>
<token pi="O">av</token>
<token pi="geographic">Göteborg</token>
<token pi="O">.</token>
</sentence>
<sentence>
<token pi="O">Han</token>
<token pi="O">pratar</token>
<token pi="O">engelska</token>
<token pi="O">och</token>
<token pi="O">svenska</token>
<token pi="O">såklart</token>
<token pi="O">.</token>
</sentence>
<sentence>
<token pi="O">Vi</token>
<token pi="O">talar</token>
<token pi="O">engelska</token>
<token pi="O">med</token>
<token pi="O">varandra</token>
<token pi="O">,</token>
<token pi="O">men</token>
<token pi="O">jag</token>
<token pi="O">lär</token>
<token pi="O">mig</token>
<token pi="O">svenska</token>
<token pi="O">och</token>
<token pi="O">han</token>
<token pi="O">lär</token>
<token pi="O">sig</token>
<token pi="other">polska</token>
<token pi="O">.</token>
</sentence>
</text>
If you want to re-do the process (e.g. change the text or requested annotations), you can remove all that was created using:
sparv clean --allAnd then run Sparv again.
With this (hopefully helpful) little guide you should now be able to apply this annotation to data of your choosing.
Remember! If you intend for this to be a part of a de-identification pipeline, it should not replace a manual annotation, but may assist it, as the models cannot guarantee the discovery of all pieces of personal information with 100% accuracy.
Useful links
References
Elisabeth Eder, Michael Wiegand, Ulrike Krieg-Holz, and Udo Hahn. 2022. “Beste Grüße, Maria Meyer” — Pseudonymization of Privacy-Sensitive Information in Emails. In Proceedings of the Thirteenth Language Resources and Evaluation Conference, pages 741–752, Marseille, France. European Language Resources Association.
Nikolai Ilinykh and Maria Irena Szawerna. 2025. “I Need More Context and an English Translation”: Analysing How LLMs Identify Personal Information in Komi, Polish, and English. In Proceedings of the Third Workshop on Resources and Representations for Under-Resourced Languages and Domains (RESOURCEFUL-2025), pages 165–178, Tallinn, Estonia. University of Tartu Library, Estonia.
Maria Irena Szawerna, Simon Dobnik, Ricardo Muñoz Sánchez, Therese Lindström Tiedemann, and Elena Volodina. 2024. Detecting Personal Identifiable Information in Swedish Learner Essays. In Proceedings of the Workshop on Computational Approaches to Language Data Pseudonymization (CALD-pseudo 2024), pages 54–63, St. Julian’s, Malta. Association for Computational Linguistics.
Maria Irena Szawerna, Simon Dobnik, Ricardo Muñoz Sánchez, and Elena Volodina. 2025. The Devil’s in the Details: the Detailedness of Classes Influences Personal Information Detection and Labeling. In Proceedings of the Joint 25th Nordic Conference on Computational Linguistics and 11th Baltic Conference on Human Language Technologies (NoDaLiDa/Baltic-HLT 2025), pages 697–708, Tallinn, Estonia. University of Tartu Library.
Oleksandr Yermilov, Vipul Raheja, and Artem Chernodub. 2023. Privacy- and Utility-Preserving NLP with Anonymized data: A case study of Pseudonymization. In Proceedings of the 3rd Workshop on Trustworthy Natural Language Processing (TrustNLP 2023), pages 232–241, Toronto, Canada. Association for Computational Linguistics.