

This blog is a piece of opinion where I sketch the process of developing NLP-based applications for second language learning and look at the process from the point of view of typical (mis)conceptions and challenges, as I have experienced them. Are we over-trusting the potential of NLP? Are teachers by definition reluctant to use NLP-based solutions in classrooms? How, if at all, can academic universities ensure sustainability of the developed applications?
1 Introduction
Natural Language Processing (NLP) and Language Technology (LT) deal with the analysis of natural languages in written and spoken form, and are becoming ubiquitous in the modern (digitized) society. NLP and LT have the potential to influence people’s everyday life, just as Google has already proven, without lay people even knowing that they owe that to development of Language Technology. The areas where we see LT’s (omni)presence daily include translation (e.g. https://translate.google.com/ ), effective information search (e.g. www.google.com), ticket reservation, lexicon services, e.g. Oxford English dictionary online (Simpson and Weiner, 1989), etc. Duolingo (von Ahn, 2013; www.duolingo.com/) and Rosetta Stone (www.rosettastone.eu/), among others, have proven that language technology can also boost second and foreign language (L2) learning.
Intelligent Computer-Assisted Language Learning (ICALL) commonly refers to CALL enhanced with NLP technologies which are able to process human language in a fine-grained manner that allows for, among others, the analysis of learner language or language materials (Borin, 2002b). Although a number of examples of the successful integration of ICALL systems in language instruction exists (see Amaral and Meurers (2011) for some examples), there are a number of challenges to consider when developing such systems. The book by Heift and Schulze (2007) has been called a ”depression diary” of ICALL since it describes system after system which never got used by the intended user – with only a few lucky exceptions.
Below, I first give an overview of a typical development cycle for ICALL applications and then present a collection of the major challenges involved in this process seen from the point of view of an NLP researcher.
2 ICALL application development cycle
In ICALL application development, there is a sequence of steps that need to be followed, the most important ones are outlined in Figure 1. The first step is to decide on a target group: Who should be able to learn using this application: children or adults? Healthy learners or learners with some disabilities (e.g. dyslexia)? Analphabets or students with some prior education? Is this application aimed at self-study or at supporting teacher-led lessons? Each target group naturally poses its own challenges.

Figure 1: ICALL application development cycle
In the second step, ICALL researchers and developers need to decide what language skill or competence to focus on. Language learning is traditionally described through knowledge of three competences - vocabulary, grammar and phonetics/pronunciation, and four main skills – reading, writing, speaking and listening. Under each of these headings there are a number of subskills that need to be addressed as well, the latter are well-described in the Common European Framework of Reference (CEFR) document (Council of Europe, 2001).
Depending upon the answers to steps one and two, step three addresses the need of data and resources. If, for example, the focus of the application is the support of the L2 writing process in healthy adults, there is a need of data that reflects the target group’s writing, and a number of resources based on that data, such as typical errors, successful usage of constructions, etc. Which words do they know well? Which words do they have problems with? Are there any troubles with grammatical structures? Do they need access to lexical or encyclopedic resources? Is there any need for instructional feedback and explanations?
Once, the data and resources are in place, automatic solutions, algorithms and tools, indicated in step four (Fig. 1), can be developed. This step results in a “black-box” solution, where multiple existing and new methods, resources and tools are combined to solve well-defined practical tasks. For example, for L2 writing support, one can name spell-checkers, grammar checkers, analysis of discourse and topics, automatized feedback about what should be improved, etc.
When steps 1-4 are solved, it is time for step five: to develop a user-oriented (prototypical) application with a user interface for digitized access through desktop and/or mobile devices. Multiple issues in human-machine interaction and questions of sustainability of the selected programming language( s) need to be considered.
The prototype needs to be evaluated with students and teachers (step six), and following the results of the evaluation, an iteration of improvements is usually necessary to make the algorithms and application usable before the release. Accompanying documentation is due in this step.
Step seven addresses the question of maintenance of the developed prototype/application to ensure its sustainability. As the practice shows, universities (i.e. researchers) do not have time or funding to maintain applications beyond the proof-of-concept/hypothesis process, whereas research funding agencies do not grant funding to mere systems development and maintenance. This often results in a prototype’s fast ageing, as programming languages stop being supported or become outdated and incompatible with up-to-date desktop browsers and mobile technologies.
3 Feats, defeats and challenges
3.1 Overgeneralizing
It is typical to generalize L2 learning as a homogeneous process for all target groups. However, even the style of learning for healthy learners would be different depending on their age, i.e. at schools (young age) and later (adult learning). To take one example, texts that children will be able to read and understand would be different from what an adult learner would be able to cope with due to the world knowledge that one can rely on. Adults are also more inclined to engage in a self-study process of language learning compared to children, hence the need for different solutions for the two age groups.
3.2 Over-trusting
There is a common opinion (that I used to share, I have to admit) that language technology can easily automatize the production of language learning materials and the assessment of learner’s performance; you can just use off-the-shelf tools and algorithms, tweak them a bit, and assemble those into a pipeline for language learning purposes. A very fast and effective process.
Unfortunately, this is only half-true. Off-the-shelf solutions are developed on normative language practices. What we see during L2 learning is a deviating type of language, pretty much resembling that of historical texts as compared to modern texts. The off-the-shelf tools need, therefore, to be complemented by a number of solutions aimed at this particular type of target group. To give an example, the following excerpt contains orthographic, grammatic, capitalization and word order deviations from standard English that would optimally need to be normalized before applying standard tools.
It is in august I rememeber day was rain. i filt me little cold because i came from worm land.
3.3 Under-estimating
Large-scale (and often language-independent) automatic solutions for second/foreign language learning are not always optimal, since development of language learning applications is in many cases dependent on the target language, and often even on students’ first languages (L1). This means that ICALL applications need to be built on resources and algorithms that are specifically developed for language learners, i.e. resources that rely on research and specialist efforts, for example taxonomies of typical errors in writing, vocabulary scope at different levels of language proficiency, grammatical structures that are learned, etc.
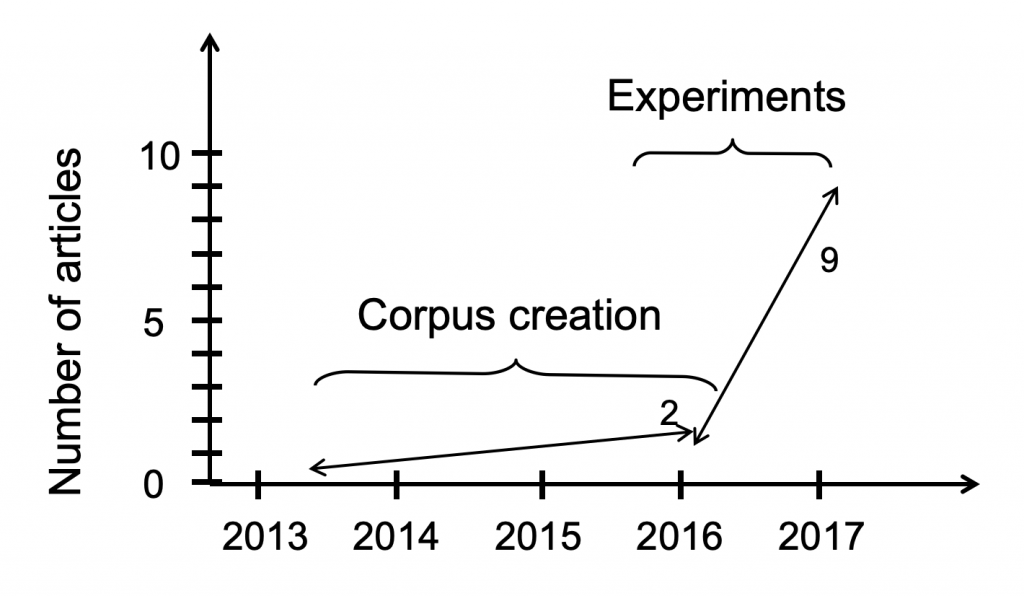
Figure 2: Data creation versus exploitation, measured in number of years and published papers (from my personal experience)
As usual, the process of getting data on your own is extremely time-consuming. L2 data is maybe especially time-consuming since L2 essays (and other types of L2 data) are very difficult to acquire to start with. You need to be in touch with some enthusiastic teachers who would be willing to sacrifice their time on explaining permits and filling in socio-demographic forms with their students instead of using that time for proper teaching. Adding manual (e.g. error) annotation is a further complication on the way.
There is an interesting fact many NLP researchers – including myself - have observed through their practices: the period for data collection and preparation is very long and ungrateful, when measured in number of publications. However, as soon as the data is ready, the number of publications shoots up dramatically, as shown in Figure 2.
In recent years there have been a number of attempts to overcome the lack of a sufficient amount of annotated data tailored for a task, for example crowdsourcing and domain adaptation. Crowdsourcing is an emerging way of collecting data. Among its advantages low time investments and enthusiasm of the crowd are often named. Duolingo is, for instance, translating the web by using learners of different languages (von Ahn, 2013), Lärka for Swedish has used exercise answers to collect a database of L2 spelling errors (Volodina and Pijetlovic, 2015), and the list of examples goes on. However, in a L2 learning context, the definition of a “crowd” becomes more that of a “target group”, and other benefits may or may not hold their value: in order to crowdsource data, a system has to be already designed and running, i.e. costs on systems development and maintenance have to come from some source (see 3.8 below). Also, the enthusiasm of the crowd is often pretty overstated.
3.4 Overlooking (legal issues)
Talking about data, we would also need to alert you to issues around Copyright, Personal integrity act, GDPR requirements, pseudonymization issues, etc (Megyesi et al. 2018). Data that is not collected according to the legal standards cannot be shared with other researchers, and rests comfortably in some individual researchers’ desks after years and years of efforts to collect and annotate it - which means it cannot be experimented with and fed in into an ICALL system. Even worse, you may realize way too late that the data you have collected cannot be used even for your individual studies - and you face the risk of throwing out of the window several years of your work.
3.5 High expectations
As an ICALL researcher, you expect teachers to be enthusiastic about a possibility of using automatic NLP-based solutions in their practices, since – you believe – the new tools can ease up the burden on a teacher, and why not even revolutionize the teaching practices?
From my experiences (see also e.g. https://eltjam.com/geoff-jordan-vs-duolingo/), it is a challenge to find practicing teachers who are interested in integrating or even testing new technologies in their already established routines. Overworked and overloaded, teachers generally do not have time or energy to expand their already huge workload. It is difficult even to get them interested in such a “tiny” thing as essay collection. You are lucky if one of them is willing to collaborate with you. You go around treasuring that one precious teacher contact.
3.6 Talking different languages
Another challenge is teachers’ scepticism towards automatic solutions. You spend years on trying to solve a problem that you consider important and challenging, let’s say, selecting good distractors for multiple-choice exercises. Once you think your solution is mature, you ask teachers to test it, and all you hear is that “we don’t work this way, we practice communication approach”, and ”why don’t you follow our teaching for a while before deciding how you want to help us?”.
The topic of lack of understanding and interest between the two groups - teachers and ICALL researchers - has been discussed before (Borin, 2002a), and though there seems to be an improvement in the situation, in fact not much has changed. Teachers want to have control over the process of teaching, and fully automated solutions are met with distrust. Over the years, some researcher groups, notably at Educational Testing Services, have gradually reduced the amount of automatic processes, handing over to teachers the process of selection of materials, decisions on exercise details and assessment, providing only semi-automatic support for each of the steps (Burstein et al., 2012). In other examples, only half of the process is automatized, as for example in Werti/VIEW ( http://sifnos.sfs.uni-tuebingen.de/WERTi/ ) where teachers select their own texts of interest, while the plug-in automatically converts that text into an exercise (Meurers et al., 2010).
3.7 Skipping user evaluation
There is an observed tendency that NLP researchers interpret system evaluations as performance of the algorithms measured in terms of accuracy and F-score. However, systems aimed at L2 users – and quite demanding users where errors are not really tolerated – analyzing users’ interaction with such systems provides valuable feedback (Paroubek et al., 2007). Often, this will play a key role in deciding whether the system will or will not be accepted in schools.
User-based evaluations of applications are, however, still not very common, especially on a larger scale. This may depend on the fact that the process is rather time-consuming and access to financial resources may also be required. One needs to establish and maintain contact with the relevant user group(s). Conducting such evaluations for ICALL systems usually requires the availability of language teachers or learners who often have time constraints depending on their syllabus. During the evaluation, metadata is usually collected (e.g. age, other languages spoken), which can be valuable later during the analysis of the results. It is of utmost importance that evaluators grant their consent to the use of both the metadata and the evaluation data collected. Preparing the evaluation material needs careful planning and some preparation time to make sure that the objectives are clear and the format of the evaluation is adequate (Bevan, 2007). Moreover, a suitable medium through which to perform the evaluation has to be found and, in absence of it, one may have to opt for developing a solution tailored to the task at hand. Finally, the evaluation data needs to be analyzed and presented with the appropriate quantitative or qualitative methods. Here, measures from other relevant fields such as applied linguistics and language testing may be useful paths to explore. Examples of ICALL-related studies with user evaluations include, for example, Burstein et al. (2013) describing the results of an evaluation of Language Muse, a web-based support tool for teachers, and Pilán et al. (2013) presenting a study on sentence readability for Swedish as a second language.
3.8 Self-maintenance
Once you are done with the evaluation of a prototype, it is easy to be misled into thinking that now you just have to deploy the application in real-life. As experience shows, all applications need continuous maintenance to keep up with technologies that change all the time. There is a need of funding for this, which can either come from a commercial side, i.e. through making the developed product commercial, or through some special type of funding which would include systems development and maintenance, for example infrastructure-funding. The first option will jeopardize the openness of the resource to the public; the second would guarantee free access for the public, but entails conversion of a language learning application into a research infrastructure to secure funding. That conversion means a focus shift to a new target group: instead of concentrating on the needs of L2 learners, the main focus would be on the interests of L2 researchers, and thus the L2 activities should be designed in such a way that they can help elicit L2 research data, hopefully combined with some positive learning effect. In the long run, however, this promises to be a win-win solution for both sides. Just don’t give up too early.
3.9 Keeping to the comfortable zone
Maybe the most common pitfall in ICALL development is that after starting on an ICALL project the researcher might soon realize how huge the task is and stop half-way. The data and algorithms will continue to be stored comfortably in the researcher desk/computer, the potential tool remaining in a status of a “researcher toy” and nothing more. One can ask whether this indicates lack of motivation to invest time into application development? Or maybe these researchers are more interested in experiments with algorithms per se not caring about what happens next? Or is it a result of language and funding policy?
4 Concluding remarks
In this short overview of the ICALL application development processI have tried to summarize experiences, defeats and insights that I am aware of. I know that there are many more challenges and potential pitfalls apart from the ones described here. However, I hope that being aware of these experiences may save some other researchers from making the same mistakes.
References
Luiz A Amaral and Detmar Meurers. 2011. On using intelligent computer-assisted language learning in real-life foreign language teaching and learning. ReCALL, 23(01):4–24.
Nigel Bevan. 2007. Designing a user-based evaluation. National Physical Laboratory, Teddington, Middlesex, UK.
Lars Borin. 2002a. What Have You Done For Me Lately?... In EUROCALL 2002, PRECONFERENCE WORKSHOP ON NLP IN CALL, AUGUST 14, 2002, JYVÄSKYLÄ, FINLAND. Citeseer.
Lars Borin. 2002b. Where will the standards for intelligent computer-assisted language learning come from? In Proceedings of the LREC Workshop on International Standards of Terminology and Language Resources Management, pages 61–68.
Jill Burstein, Jane Shore, John Sabatini, Brad Moulder, Steven Holtzman, and Ted Pedersen. 2012. The language muse system: Linguistically focused instructional authoring. ETS Research Report Series, 2012(2).
Jill Burstein, John Sabatini, Jane Shore, Brad Moulder, and Jennifer Lentini. 2013. A user study: Technology to increase teachers’ linguistic awareness to improve instructional language support for english language learners. In Proceedings of the Workshop on Natural Language Processing for Improving Textual Accessibility, pages 1–10.
Council of Europe. 2001. Common European Framework of Reference for Languages: learning, teaching, assessment. Press Syndicate of the University of Cambridge.
Trude Heift and Mathias Schulze. 2007. Errors and Intelligence in Computer-Assisted Language Learning: Parsers and Pedagogues. Routledge.
Detmar Meurers, Ramon Ziai, Luiz Amaral, Adriane Boyd, Aleksandar Dimitrov, Vanessa Metcalf, and Niels Ott. 2010. Enhancing authentic web pages for language learners. In Proceedings of the NAACL HLT 2010 Fifth Workshop on Innovative Use of NLP for Building Educational Applications, pages 10–18. Association for Computational Linguistics.
Patrick Paroubek, Stéphane Chaudiron, and Lynette Hirschman. 2007. Principles of evaluation in natural language processing. Traitement Automatique des Langues, 48(1):7–31.
Ildikó Pilán, Elena Volodina, and Richard Johansson. 2013. Automatic selection of suitable sentences for language learning exercises. In 20 Years of EUROCALL: Learning from the Past, Looking to the Future. Proceedings of EUROCALL., pages 218–225.
John Simpson and Edmund SC Weiner. 1989. Oxford English dictionary online. Oxford: Clarendon Press. Retrieved March, 6:2008.
Elena Volodina and Dijana Pijetlovic. 2015. Lark trills for language drills: Text-to-speech technology for language learners. In Proceedings of the Tenth Workshop on Innovative Use of NLP for Building Educational Applications, pages 107–117.
Luis von Ahn. 2013. Duolingo: learn a language for free while helping to translate the web. In Proceedings of the 2013 international conference on Intelligent user interfaces, pages 1–2. ACM.