

This blog is based on a joint work by Elena Volodina, Therese Lindström Tiedemann and Yousuf Ali Mohammed within the RJ-funded project L2 profiles. Three annotators have contributed to this work: Stellan Petersson (University of Gothenburg), Beatrice Silén (University of Helsinki ) and Maisa Lauriala (University of Helsinki).
Do you know how many prefixes or suffixes the Swedish language has? Which ones? Different sources state different numbers, e.g Thorell (1984) lists approx. 90 derivational suffixes and about 50 derivatonal prefixes; Hultman (2003) names 200 derivational affixes (counting prefixes and suffixes together). In our work, we have analyzed 16.000 vocabulary items and as a result listed 259 derivational suffixes , 155 derivational prefixes, 4000+ roots and more - with examples for each of them (Volodina et al., 2021). We offer you to inspect our results and apply our new resource, CoDeRooMor*, for your purposes - be it within linguistic, pedagogical, language technology or any other context where Swedish non-inflectional morphology may be of interest.
To create the dataset, we have used two corpora relevant for Second Language (L2) Swedish (under the assumption that this vocabulary would represent the most frequent vocabulary items): course book corpus, COCTAILL (Volodina et al., 2014) and learner-written essays from the SweLL-pilot corpus (Volodina et al., 2016). Based on the two corpora we have generated a list of vocabulary items (see a graph below for a better overview) and used it for annotation.
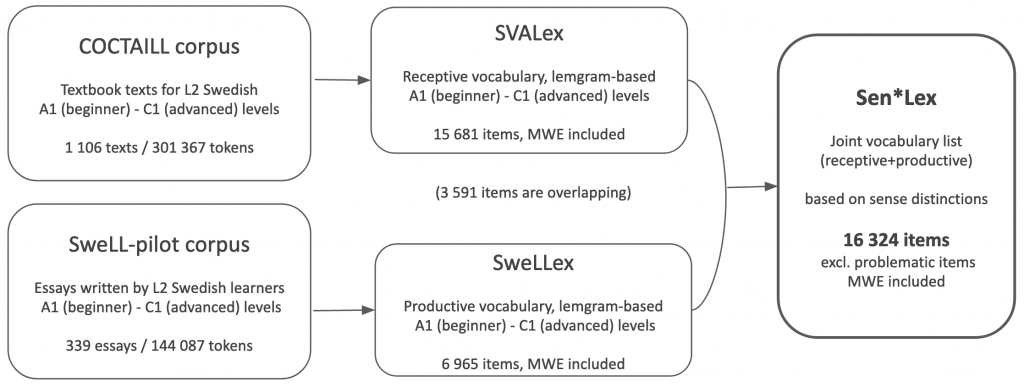
The approximately 16.000 lexical items in the vocabulary list have been manually segmented into word-formation morphemes, and labeled with their categories, such as prefixes, suffixes, roots, etc. Where available, we consulted the SAOL/SO analysis of vocabulary for morpheme boundaries. Besides, word-formation mechanisms, such as derivation and compounding have been associated with each item on the list.
Three annotators under the leadership of a project researcher performed the annotation according to a set of detailed guidelines. The annotator work was supported by the annotation tool Legato (Alfter et al., 2020). Inter-annotator agreement in terms of Krippendorff's alpha, calcualted on a subset of items, reached 0,86-0,94 depending on the type of annotation - (1) segmenting into morphemes, (2) labeling morphemes, (3) labeling word formation mechanism - which is a token of high quality of annotation.
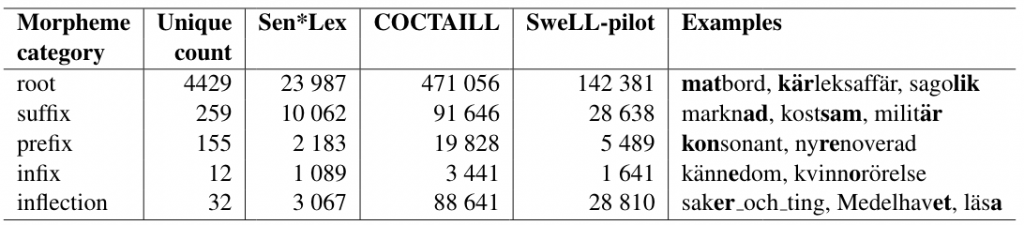
As a result, we have the following statistics over derivational morphemes (note that the "inflection" in the table describes inflections observed in lexicalized vocabulary items and in a few other cases as described in Volodina et al. 2021):
The resource has been organized in two ways: by lemgram as the main unit and by morpheme as the main unit, as shown by short excerpts below.


Given the ”gold” nature of the resource, it is possible to use it for empirical studies as well as to develop linguistically-aware algorithms for morpheme segmentation and labeling (cf. statistical sub-word approach). We are currently working on making CoDeRooMor available through the Swedish L2 morphological profile, where, among others, we will offer searches and filtering by the so called Word Family principle (e.g. words sharing the same root). You will find more details about this resource in Volodina et al. (2021).
The resource is freely available through Språkbanken-Text. If you use CoDeRooMor, please cite our recently accepted paper (Volodina et al., 2021).
_________________________
* CoDeRooMor stands for Compounding, Derivation, Root Morphology and more
REFERENCES
David Alfter, Therese Lindström Tiedemann and Elena Volodina. 2019. LEGATO: A flexible lexicographic annotation tool. Nodalida 2019, Turku, Finland. LiUP Press. [pdf]
Tor G. Hultman. 2003. Svenska akademiens språklära. Svenska akademien.
Olof Thorell. 1984. Att bilda ord. Vol. 1. Skriptor, 1984.
Elena Volodina, Ildikó Pilán, Stian Rødven Eide and Hannes Heidarsson 2014. You get what you annotate: a pedagogically annotated corpus of coursebooks for Swedish as a Second Language. Proceedings of the third workshop on NLP for computer-assisted language learning. NEALT Proceedings Series 22 / Linköping Electronic Conference Proceedings 107: 128–144. [pdf]
Elena Volodina, Ildikó Pilán, Ingegerd Enström, Lorena Llozhi, Peter Lundkvist, Gunlög Sundberg, Monica Sandell. 2016. SweLL on the rise: Swedish Learner Language corpus for European Reference Level studies. Proceedings of LREC 2016, Slovenia. [pdf]
Elena Volodina, Yousuf Ali Mohammed & Therese Lindström Tiedemann. 2021 (In press). CoDeRooMor: A new dataset for non-inflectional morphology studies of Swedish. Proceedings on Nodalida 2021.