

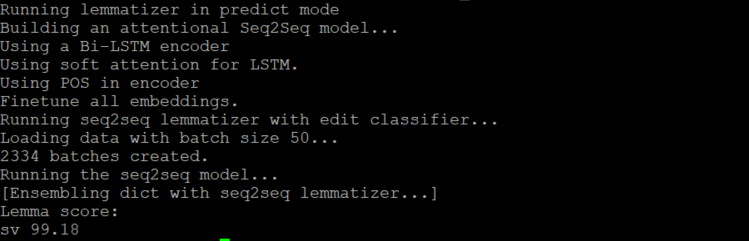
We have added a pretrained model for lemmatization of Swedish text to our model collection. The model was trained and tested on SUC3 using the Stanza package and achieves a very high accuracy of 99.18.
The drawback of this model is that SUC3 lemmatization and part-of-speech annotation does not exactly match that in Saldo, which is used by Sparv to annotate the resources available via Korp. The advantage, however, is that the model always produces a guess (and usually a correct one), while the current version of Sparv sometimes cannot do that. The new version of Sparv (coming soon) will probably combine the two approaches.
Using the model does not require deep knowledge of natural language processing or advanced programming skills.
More to come.