

Shafqat Mumtaz Virk, Harald Hammarström, Markus Forsberg, Søren Wichmann
The diversity of 7000 languages of the world represents an irreplaceable and abundant resource for understanding the unique communication system of our species (Evans and Levinson, 2009). All comparison and analysis of languages departs from language descriptions — publications that contain facts about particular languages. The typical examples of this genre are grammars and dictionaries (Hammarström and Nordhoff, 2011).
Until recently, language descriptions were available in paper form only, with indexes as the only search aid. In the present era, digitization and language technology promise broader perspectives for readers of language descriptions. The first generation of enhanced search tools allow searching across many documents using basic markup and filters, and modern natural language processing (NLP) tools can take exploitation arbitrarily further.
Enumerating the extant set of language descriptions for the languages of the world is a non-trivial task. Thanks to the Glottolog project, this task is now complete in the sense that the most extensive description for every language is known (Hammarström and Nordhoff, 2011). These references, along with a large body for further entries for most languages, are included in the open-access bibliography of (Hammarström et al., 2019). Figure 1 shows an example of a typical source document, in this case a German grammar of the Ewondo [ewo] language of Cameroon.

Undoubtedly, bibliographies like above are very useful resources in themselves, what will be even more useful, also much needed, is availability of actual documents in machine readable format, ideally, accessible through tools suitable for easy access and exploration e.g. through corpus infrastructure tools. This was, exactly, one of the major aims of EU funded DreaM project.
Prior to and during the project, a core subset of more than 40,000 publications — including the most extensive description for 99% of the worlds languages — has been digitized or obtained in born-digital form. The set of digital documents has been subjected to optical character recognition (OCR) to obtain a machine readable version and to recognize the meta-language of the document. Each item has been manually annotated with the language(s) described in it (the object-language), the object language ISO code, the language used to describe it (the meta-language), the number of pages , the type of document (e.g., grammar, dictionary, phonology, sociolinguistic study, overview etc.), document title, document author, and the production year. A BibTex entry of the following type is being maintained for each document.
@book{g:Lichtenberk:Manam,
author = {Frantisek Lichtenberk},
title = {A Grammar of Manam},
publisher = {Honolulu: University of Hawaii Press},
series = {Oceanic Linguistics Special Publication},
volume = {18},
pages = {xxiii+647},
year = {1983},
glottolog_ref_id = {55327},
hhtype = {grammar},
inlg = {English [eng]},
isbn = {9780824807641},
lgcode = {Manam [mva]},
macro_area = {Papua}}
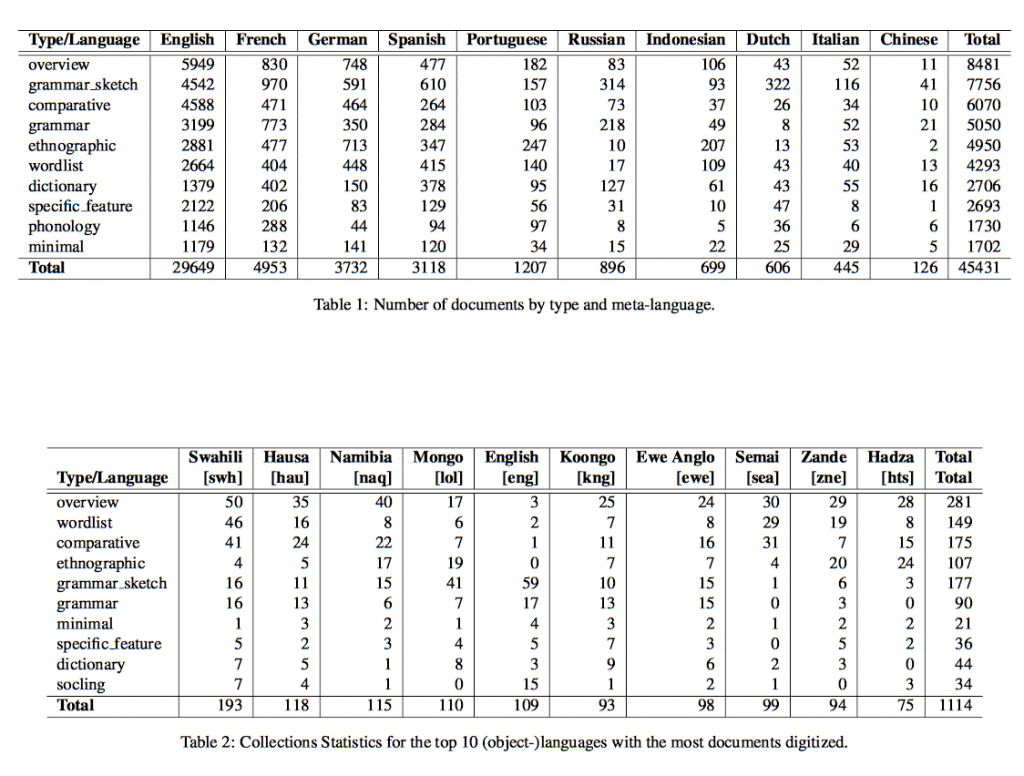
Table 1 shows the number of documents collected and digitized. For space reasons, only the top 10 (with respect to the number of documents in the collection) document types (e.g. grammatical description, word list, dictionary, etc.), and meta languages are listed. Table 2 shows statistics about the type and number of documents per natural language (i.e. object language). Again, only the top 10 languages with respect to the number of documents and document types are shown.
Documents belonging to any of the types ’grammar sketch’, ’grammar’ and ’specific feature’ were separated from the collection, and this is the set that have been enriched with a few lexical and syntactical annotations -- as will be described shortly-- and is being described in this blog. The reason for this separation is that only these document types contain prose descriptions which is a required format for the corpus infrastructure tool that we have chosen (to be briefed later) to make the documents explorable through. The other documents types (e.g. dictionaries and word lists) are non-prose in their format and we have plans to process and make them available through other suitable corpus infrastructure tools in the near future.
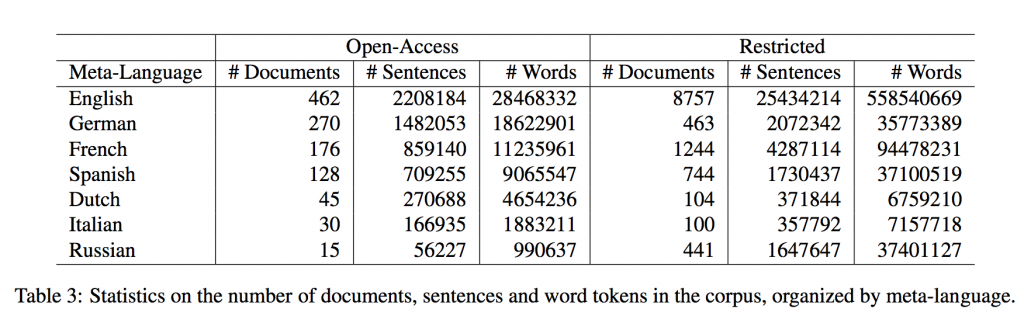
The separated set set was divided into two subsets (English and non-English): one with documents written in English and the other in the remainder of the meta-languages. Further, according to the copyright status of individual document, each of the two subsets (English and non-English) were further divided into open and restricted sets. The former consists of all those documents that are at least a century old and/or do not have any copyrights, while the latter set contains documents which have copyrights and, hence, can not be released as an open-access corpus. Table 3 shows some statistics of the both the open and restricted parts of the corpus language wise.
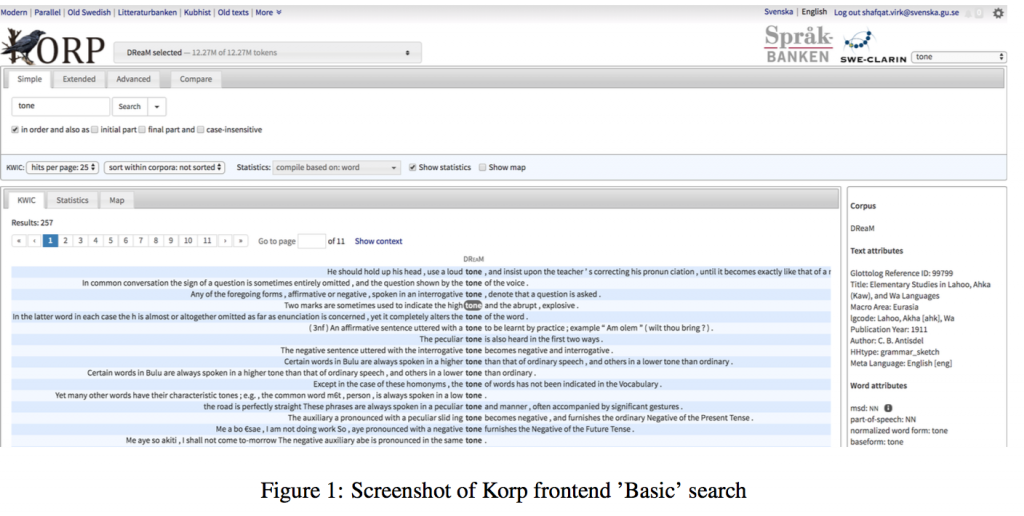
The open-access set, both the English and non-English, is being made accessible through Korp (Borin et al., 2012), which is a system in the corpus infrastructure developed and maintained at Språkbanken (the Swedish language bank). It has separate backend and frontend components to store and explore a corpus. The backend is used to import the data into the infrastructure, annotate it, and export it to various other formats for down loading. For the annotations, it has an annotation pipeline that can be used to add various lexical, syntactic, and semantic annotations to the corpus using internal as well as external annotation tools. In our case, we have used Stanford’s CoreNLP toolkit (Manning et al., 2014) for sentence segmentation, tokenization, lemmatization, and POS tagging, and dependency parsing of the English dataset. The Non-English set was annotated with POS tags, but no syntactic parsing. This is mainly because of the unavailability of appropriate annotation and parsing tools for languages other than English. The frontend provides basic, extended, and advanced search options to extract and visualize the search hits, annotations, statistics, and more. Figure 1 shows a screenshot of Korp frontend. It shows the hits of a basic free-text search, when searched for the string ‘tone’. The left-hand pane shows the sentences retrieved from all documents in the corpus which contained the string ‘tone’, while the right hand pane shows the text-level as well as the word-level attributes of the selected word (i.e. ‘tone’ highlighted with black back- ground). A simple, yet very useful use-case of such a search could be to retrieve all sentences from all the documents in the corpus which contains the term ‘tone’, and then analyze them in a quest to know which languages do or do not have tones. The search can be restricted (or expanded) to various word and text level attributes using the ‘Extended’ search tab (e.g. search only through a single document, search for a particular POS, or any combination of the attributes, etc.)
The open-access corpus can be accessed using the direct link (https://spraakbanken.gu.se/korp/?mode=dream#?lang=en) and can also be reached via the Korp interface.