

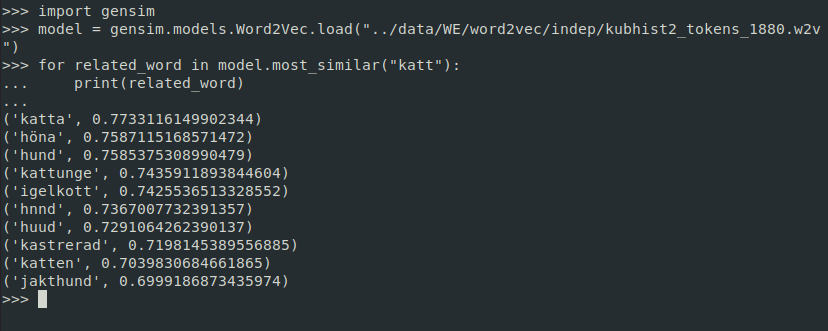
Yesterday, we have released word embedding models trained on our historical newspaper archive, Kubhist 2. Word embedding models represent words using vectors and place them in their semantic neighbourhood such that words that are similar are closer together. Thus they allow to easily look for semantic similarity between words as well as detect relations. We have released diachronic models, one for each 20-year period of Kubhist 2. The interesting feature of diachronic embeddings is that they allow to for the study of a word's semantics over time. The models are currently available on Zenodo, and will be available via the SBX page shortly. A thorough description is soon to appear in the Journal of Open Humanities Data.
3 december 2020