

I den här bloggen ägnar vi oss åt datorers förmåga att läsa analog text. Denna förmåga är nuförtiden ofta mycket god: det är inte bara tryckt text utan även handskrift som datorerna kan förmås att uttolka. Det goda resultatet kan emellertid helt utebli om inte manegen först krattas ordentligt. En datormodell som är tränad att hantera bilder av text, den behandlar nämligen varje bild den utsätts för som just en bild av en text. Matar man modellen med en bild av en ballong, försöker den således läsa ballongen och transkribera den. Ett viktigt förarbete är därför att freda modellen från ballonger och annan icke-text.
Tryckt text
Att datorer kan läsa inskannad text är vi numera rätt vana vid. Tekniken kallas OCR, vilket står för Optical Character Recognition, och den är ofta inbyggd i webbläsare och pdf-program. När man exempelvis studerar äldre böcker som digitaliserats av Google kan man både söka i texten och kopiera passager. Bild 1 nedan visar ett uppslag ur Almquists Svensk språklära (fjärde upplagan) från 1854, där drygt fyra rader har markerats på samma sätt som man kan markera text i ett ordbehandlingsprogram eller på en webbsida.

Bild 1. OCR-behandlat uppslag ur Svensk språklära (1854)
För en mänsklig läsare är det lätt att se samhörigheten mellan Almquists text och t.ex. den här bloggtexten. Stavningen är förstås annorlunda i vissa avseenden, men i allt väsentligt hanterar mänskliga läsare språkläran och bloggen på samma sätt. För en dator är det dock två helt olika typer av information. Språkläran är, när den först träder in i den digitala världen (genom Googles försorg), inget annat än en bild. Vi behöver instruera datorn att denna bild innehåller återkommande mönster som ska översättas till tecken. Det är just en sådan instruktion som OCR-tekniken utgör.
Handskriven text
Eftersom de enskilda tecknen i språkläran har frambringats av blytyper är variationen i hur exempelvis ett r eller ett b ser ut mycket begränsad. Att alla tecken av samma sort således är väldigt lika varandra (och i förlängningen klart skilda från andra tecken) gör konverteringen av bild till text lättare. Handskrivna texter utmärks däremot just av att enskilda tecken kan se lite olika ut varje gång de uppträder. Men även sådana variationer kan hanteras, så länge man instruerar datorn att variationen föreligger.
Att ”instruera” innebär i det här sammanhanget att man ger exempel på olika varianter genom att manuellt transkribera en del text och därigenom etablera en transkriptionsnyckel som datormodellen kan inlemma och sedan tillämpa på ny text av samma slag. Att således träna datormodeller att avkoda handskriven text brukar gå under beteckningen HTR, vilket står för Handwritten Text Recognition. Egentligen är det dock ingen principiell skillnad mellan OCR och HTR. Det handlar i båda fallen om att bygga en datormodell som kan känna igen visuella mönster och översätta dem till digital text.
Vi kan jämföra den tryckta texten i Bild 1 ovan med den handskrivna i Bild 2 nedan. Den handskrivna texten är skriven på dialekt (bohuslänska) och avviker från den tryckta på fler sätt än att de enskilda tecknens utformning varierar i större utsträckning. Som vi kan se innehåller den en del tecken som saknar motsvarighet i det svenska alfabetet; vi ska strax återkomma till specialtecknen och deras digitala korrelat. Men först ska vi uppehålla oss vid vad som förenar den tryckta och den handskrivna texten. De tryckta typerna varierar faktiskt mer i utseende än vad man kan först kan tro, och de handskrivna tecknen varierar inte hur mycket som helst, eller kanske snarast: inte på vilket sätt som helst.
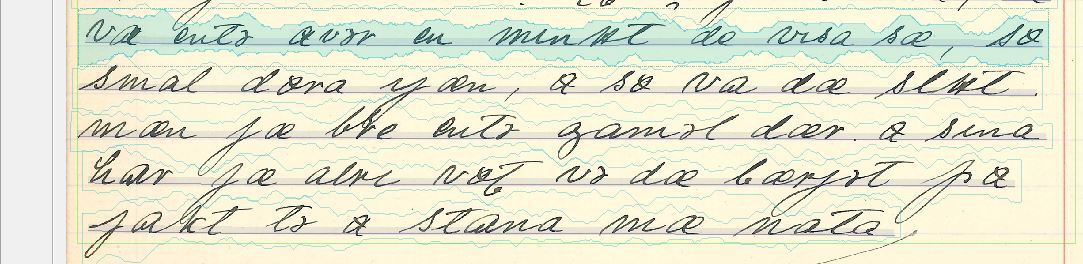
Bild 2. HTR-behandlad sekvens ur handskriven dialekttext från Isof i Göteborg (iodg00027_1, s. 143)
I Bild 3a nedan har vi lyft ut två instanser av tecknet för <a> ur vardera texter. Det är förstås uppenbart att den visuella närheten mellan de två a-instanserna är större i det tryckta exemplet än i det handskrivna. Ändå står det klart att de två tryckta a-instanserna inte är helt identiska. Det framgår också att de två handskrivna a-instanserna visserligen har lite olika lutning och utformning men ändå uppvisar tydliga visuella paralleller. Poängen är helt enkelt att skillnaden mellan tryckt och handskriven text ifråga om visuell teckenvariation trots allt är en gradskillnad, inte en artskillnad. Bild 3b visar en så kallad obfuskeringsmatris, som illustrerar hur ett handskrivet a har översatts till ett koordinatformat som kan ligga till grund för teckenigenkänning.
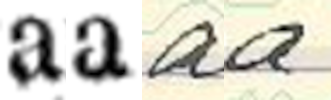
Bild 3a. Tryckta och handskrivna a-varianter

Bild 3b. Obfuskeringsmatris för handskrivet <a>
I den tryckta texten finns det fler a-typer än den som visas i Bild 3a; se Bild 4 nedan. För en mänsklig läsare är det förstås uppenbart att dessa två a-varianter inte ska förstås som egna tecken utan endast som alternativa representationer av samma tecken som används dels i kursiverade sekvenser (a), dels i vissa ställningar, t.ex. direkt efter punkt (A). En datormodell måste å andra sidan matas med information om att just detta slags visuell variation, nämligen mellan ”a”, ”a” och ”A”, ska tillåtas inom ett och samma skrivtecken, så kallat grafem, medan andra varianter av liknande slag, t.ex. ”ä”, hör till ett separat grafem, nämligen <ä>.
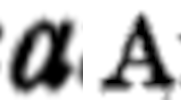
Bild 4. Fler varianter av tryckt <a>
Utrymmet för den här sortens visuell variation är faktiskt mindre i den handskrivna dialekttexten. Här råder principen att all medvetet frambringad variation mellan enskilda symboler har relevans för vilket ljudvärde symbolerna representerar. Den tryckta textens grafem svarar förstås också mot språkljud i någon mån, men något fonetiskt finlir är det inte frågan om. Som vi noterat har den tryckta textens varianter snarast typografisk funktion.
I dialekttexten tas däremot inga sådan hänsyn: visserligen används punkter för att strukturera innehållet, men några versaler i början av meningar förekommer inte i landsmålskonventionen. De a-varianter som den handskrivna texten rymmer representerar istället olika ljudvärden. Den a-symbol som uppträder i Bild 3a står för den a-kvalitet som standardspråket har i ord med kort a-ljud, som hatt. Om a-symbolens elliptiska form bryts av i nederkant så att den blir närmast w-lik (som i den första symbolen i Bild 5 nedan), representerar det den a-kvalitet som standardspråkets långa a-ljud uppvisar i t.ex. hat. Om ellipsformen å andra sidan blir avskuren av ett pennstreck i överkant (som i den andra symbolen i Bild 5), får vi ett å-ljud (som i hår).

Bild 5. Dialekttextens a-ljud som i hat respektive å-ljud som i hår.
På samma sätt som OCR-modellen behöver instrueras att bortse från viss typografisk variation behöver HTR-modellen preciseras så, att den ger t.ex. de olika versionerna av a-symbolen olika digital representation. Hur en sådan representation kan se ut visas i Bild 6 nedan; direkt efter transkriptionsraderna följer en översättning till standardsvenska. De tre a-symbolerna som vi just diskuterat svarar i den digitala transkriptionen mot /a/, /â/ och /å/. Skribenten av dialekttexten använder dessutom två olika t-tecken (som svarar mot /t/ respektive /rt/ i transkriptionen) och två olika l-tecken (/l/ och /L/ i transkriptionen). Vi kan också notera att det genomstrukna o-tecken som uppträder i handskriften motsvaras av ett versalt ö-tecken (/Ö/) i transkriptionen och att ett snabel-a (/@/) används för att återge den vokal som uppträder företrädesvis i ordändelser, och som i handskriften motsvaras av ett slags bakvänt e-tecken (ə). Slutligen svarar handskriftens genomstrukna u-symbol mot /u/ i transkriptionen och sammanslagningen (ligatur kallad) av a- och e-symboler (æ) svarar mot /ä/. I övrigt råder överensstämmelse mellan handskriftens och normalalfabetets tecken.

Bild 6. HTR-behandlad dialekttext med tillhörande transkription och översättning
Översättning av Bild 6:
’var inte över en minut det visade sig, så
small dörren igen, och så var det slut
men jag blev inte gammal där. och sedan
har jag aldrig varit vid det berget på
jakt till att stanna med natten (dvs. över natten)’
Den som vill veta mer om HTR-modeller som tränats att transkribera fonetiska dialekttexter hänvisas till Petzell (2019, 2020).
Vikten av att klassificera bildytor
Hittills har vi förbigått själva grundförutsättningen för god teckenigenkänning i alla former (tryckt och handskriven), nämligen att datormodellen vet vilken del av bilden som den ska tolka som text. Utan sådan klassificerande grundinformation kan en aldrig så precis transkriptionskapacitet i värsta fall bli helt meningslös. Problemet illustreras i Bild 7 nedan. Här har samma HTR-modell som felfritt lyckades transkribera texten i Bild 2 ovan försökt uttolka sådana visuella skiftningar i bilden som en mänsklig betraktare direkt identifierar som icke-text. En människa kan rentav skilja mellan olika former av icke-text, i det här fallet mellan en av skribenten frambringad avslutningssväng med pennan (överst i bilden) och regelrätta fläckar på pappret (mitt i, och nederst i bilden).
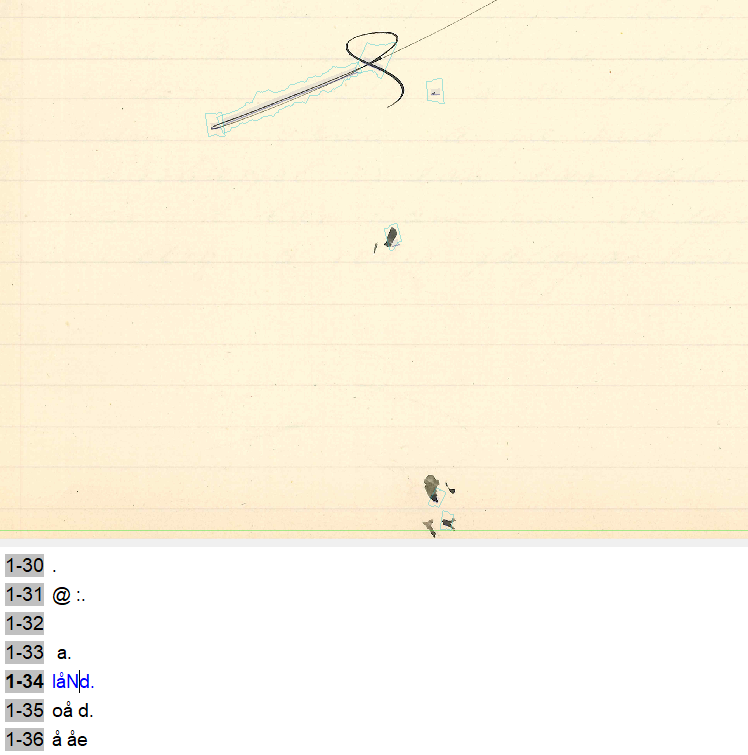
Bild 7. HTR-modell som försöker transkribera olika slags icke-text
Datormodellen är emellertid inte tränad att göra något annat än att översätta bilder till digital text. Och det är precis det den försökt göra på transkriptionsraderna under bilden. Vi människor ser direkt att här inte finns några ljudsymboler att transkribera, men modellen gör alltså så gott den kan för att ändå urskilja just sådant i den tillgängliga bilden. Den vet, så att säga, inget annat. Och resultatet blir, som vi kan se, helt oanvändbart. Ett annat exempel visas i Bild 8. Här har modellen, som är tränad att läsa frakturskrift, klarat av just det men också försökt ”läsa” den inledande bilden. Det försöket är förstås dömt att misslyckas, men som vi kan se är ändå själva bilddetaljerna rikt återgivna (fast med siffror och bokstäver).

Bild 8. Transkription av fraktur (och inledande bild).
Det behöver inte vara så extremt som i Bild 7-8. Ibland finns det textsekvenser i bilden som man av någon anledning vill att modellen ska bortse ifrån. Eller så vill man att den ska hantera viss text på ett visst sätt och annan text på ett annat sätt. För att leda modellen rätt behöver man då klassificera bildytans olika komponenter så noggrant som möjligt. Att en bildyta bara består av relevanta symboler som modellen ska analysera på en gång och på samma sätt hör egentligen till undantagen. Väldigt ofta är texten istället en del av en större struktur, som först behöver benas ut innan själva transkriberingen kan ta vid. För att underlätta klassificeringen vill man förstås automatisera hanteringen så långt det är möjligt. Det gäller då att hitta återkommande dispositionella mönster i de bildytor man ska extrahera text ur, och helt enkelt försöka få datormodellen att ”känna igen” liknande layout i nya bildytor den möter.
Vi ska nu titta närmare på två pågående projekt om automatisk klassificering av bildytor: det ena inriktar sig på arkivformulär där olika typer av text uppträder i olika fält, det andra på transkriberad dialog där talarturer anges i sidmarginalen.
Layoutanalys av arkivformulär
För att kunna transkribera text i en bild, manuellt eller med hjälp av en datormodell, behöver man först göra en layoutanalys av bilden för att identifiera textregioner och textrader. Det kan vara mer eller mindre tidskrävande beroende på materialets komplexitet. Layouten i en tabell med rader och kolumner kan exempelvis vara mer svårhanterlig än layouten i ett protokoll eller ett brev.
I följande exempel har en datormodell försökt tolka och identifiera arkivformulärens layout. I bild 9 har uppteckningen delats upp i två textregioner och de prickade linjerna har i flera fall tolkats som textrader. Textregionerna är alltså de gröna boxarna som omger texten och de rödmarkerade raderna är identifierade textrader. Det förekommer helt enkelt en hel del ”bös” som manuellt behöver städas bort. I bild 10 har uppteckningen också delats upp i två textregioner och element som inte är text har tolkats som textrader. Somliga textrader behöver dessutom sammanfogas, däribland rad 4–5 nedifrån. Detta tar inte så lång tid att åtgärda manuellt för 1 sida, men om det rör sig om hundratals eller tusentals, blir det genast ett tidskrävande liksom uniformt arbete.

Bild 9: Automatisk layoutanalys av arkivformulär (IFGH 2991, s. 5).

Bild 10: Automatisk layoutanalys av arkivformulär (IFGH 4281, s. 1).
Träna datormodeller för layoutanalys
I syfte att effektivisera layoutanalysen kan man träna datormodeller som automatiskt segmenterar bilderna utifrån det material de har tränats på. Det kan framför allt vara lönsamt när materialet till stor del har samma layout, som exemplet med de standardiserade arkivformulären. Det finns givetvis olika sätt att segmentera materialet på beroende på vilken information man är intresserad av att transkribera och huruvida det finns andra aspekter, såsom strukturella metadata i form av titel, paragraf, sidnummer, arkivstämpel etc., man vill märka upp. I bild 11 har datormodellen tränats på att bortse från den tryckta texten och enbart identifiera titeln och själva uppteckningen.

Bild 11: Automatisk layoutanalys av arkivformulär med tränad datormodell (IFGH 2768, s. 12).
Det krävs dock vanligtvis någon form av handpåläggning för en del sidor, vilket kan exemplifieras med de misslyckade resultaten i bilderna 12–13. I dessa fall behövs manuell korrigering av de identifierade textregionerna och textraderna för att den faktiska texten ska kunna transkriberas korrekt.

Bild 12: Misslyckad layoutanalys med tränad datormodell (IFGH 1163, s. 23).

Bild 13: Misslyckad layoutanalys med tränad datormodell (IFGH 1163, s. 2).
Ett annat exempel på hur en datormodell kan tränas till att automatiskt segmentera arkivformulären visas i bild 14. Modellen har i det här fallet tränats på att ignorera den tryckta texten och, utöver titel samt uppteckning, även identifiera textraderna för informantens namn, födelseår liksom födelseort. Bild 15 visar hur det kan se ut när texten väl har transkriberats. Metauppgifterna kring informanten hamnar på egna rader i transkriptionsvyn, följt av titel och uppteckning enligt originaltexten.

Bild 14: Layoutanalys med tränad datormodell (IFGH 941, s. 39).

Bild 15: Transkriptionsvyn (IFGH 941, s. 39).
Justering av textrader
Som tidigare nämnts kan textraderna behöva manuella justeringar av olika slag efter att datormodellen har genomfört segmenteringen. Det kan röra sig om en felaktig ordningsföljd, att en textrad har delats upp i två textrader, att datormodellen har utelämnat ord/tecken i slutet av raden eller dylikt. I bild 16 frångår texten den gängse formen i arkivformulären och är uppdelad i spalter samt innehåller illustrationer, vilket föranleder behovet av manuell korrigering.

Bild 16: Felaktig ordningsföljd av textrader (IFGH 2565, s.
Rad 3–2 behöver sammanfogas, rad 4 tas bort, rad 5–7 separeras för att därefter ordnas så att textraderna följer en logisk läsordning enligt bild 17.

Bild 17: Manuellt justerade textrader samt ordningsföljd (IFGH 2565, s. 28).
Ytterligare ett exempel på ett förekommande segmenteringsproblem är inskottsord, som datormodellen har en benägenhet att misslyckas identifiera. I och med att arkivformulären är standardiserade har dock sidorna en liknande textstruktur, vilket innebär att det är ett tacksamt material att arbeta med även om det förstås finns undantag. Material med en stökig layout kräver ofta en större manuell insats. Sammanfattningsvis är det syftet med projektet som styr hur layoutanalysen ska genomföras och det finns aspekter av den som kan ta mer eller mindre tid i anspråk. En noggrann layoutanalys är dock en förutsättning för en lyckad samt korrekt transkribering av originaltexten.
Layoutanalys av dialog
Vårt andra exempel gäller problemet att få en datormodell att förstå dialogstrukturen i transkriptioner av dialektinspelningar. Sådana transkriptioner, så kallade fonogramutskrifter, har genom åren gjorts sporadiskt inom Isof och dess föregångare; av det totala beståndet av inspelningar är det blott en bråkdel som har transkriptioner till sig. Ett intressant undantag utgör det gamla dialektarkivet i Lund (DAL). Här vinnlade man sig om att ”skriva ut” inspelningar så till den grad att det faktiskt är en majoritet av de äldre sydsvenska inspelningarna som nu har tillhörande transkriptioner. De är dessutom prydligt renskrivna (med skrivmaskin) och därför relativt okomplicerade att OCR-läsa.
När man väl har fått fram en digital version av transkriptionen kan denna i ett nästa steg länkas till själva inspelningen, som därmed (indirekt) blir sökbar på ett sätt som ljudande material annars aldrig kan bli. Hur denna text-och ljudlänkning går till finns det inte utrymme att gå närmare in på nu. Det förtjänar en egen framställning. Det vi ska uppehålla oss vid här är ett problem i den initiala hanteringen av själva den digitala bilden av transkriptionen. Problemet kan nästan verka banalt, men om det inte får en tillfredsställande lösning blir det avsevärt mycket svårare att i ett senare skede i processen lyckas med den efterlängtade länkningen av text och ljud.
Kärnan i problemet är att OCR-modeller har svårt att utan vidare separera metatext från regelrätt transkription. Det illustreras i Bild 18 nedan, där vi till vänster har en sida ur en inskannad transkription och till höger den tillhörande digitala output som OCR-modellen genererar. De enskilda tecknen har modellen inga problem att identifiera; det som står i originalet förs således smidigt över till digital text. Däremot hanteras inte de två siffersekvenserna optimalt. Modellen missar att det är betydelsefullt att sekvensen ”404 A” står intill just textsekvensen ”… en låga …”. Denna närhet signalerar nämligen att inspelningen fortsätter på ny skiva (A-sidan av skiva 404) just på detta ställe. Men OCR-modellen behandlar uppgiften om skivbyte i marginalen som en fristående kolumn med text, som den således placerar överst på sidan. Att det därpå följande accessionsnumret (12581) hamnar på samma rad som sidnumret (5) är också olyckligt, eftersom man gärna vill kunna separera dessa olika typer av metadata.

Bild 18. Misslyckad hantering av strukturerande marginalangivelser (sida 5 ur accession DAL 12581)
Det största problemet med OCR-modellens version av transkriptionen är emellertid hanteringen av talarangivelserna. Det är tre personer som samtalar: ”S”, ”A”, och ”J”. Och det anges noggrant i utskriften till vänster vem av dessa tre som säger vad genom att rätt personbeteckning placeras i början av varje ny replik. Som vi ser har OCR-modellen inte alls tolkat talarangivelserna på det sättet. Det är strängt taget svårt att förstå vilken princip som ligger bakom den strukturering av repliker och inledande versaler som uppträder i transkriptionen till höger. Hade modellen uppfattat versalerna som utgörande en egen textspalt skulle man vänta sig att alla 29 replikmarkeringar i originalet hamnade tillsammans. Det vi nu ser är möjligen något åt det hållet. Men varför bara 11 av de 29 markeringarna har förts över framstår som oklart. Meningslös är hanteringen av replikmarkeringarna under alla omständigheter.
Hur kan man då underlätta för OCR-modellen att hantera de strukturerande komponenterna i originalet på önskvärt sätt, utan att behöva ägna sig åt tidsödande manuell klassificering av bildytan?En möjlighet är att utgå från en befintlig modell för layoutanalys och modifiera den så att den passar de dialogiska dialektutskrifterna. Vilken typ av text den befintliga modellen extraherar spelar ingen roll – det viktiga är att själva segmenteringen och klassificeringen kan anpassas till en ny typ av bildyta. I bild 19 nedan visas en layoutanalys av samma utskriftssida som den mer rudimentära OCR-modellen alltså misslyckades med i bild 18. Som vi ser är nu såväl metadata som dialogstruktur korrekt identifierade.

Bild 19. Lyckad klassificering av samma sida ur utskriften som i bild 18.
Den klassificeringsmodell som således hanterar dialektutskriften galant bygger på en modell som från början utvecklats för något helt annat, nämligen layoutanalys av fakturor. Innehållsligt är det förstås väldigt långt mellan texttypen ”faktura” och texttypen ”dialektutskrift”. Men själva struktureringen av innehållet på bildytan uppvisar tillräckliga paralleller för att klassificeringsmodellen ska kunna återvinnas med framgång. En layoutanalys av en faktura som ursprungsmodellen genomfört visas i Bild 20. Notera exempelvis att fakturanumret uppe i hörnet rent layoutmässigt liknar dialektutskriftens accessionsnummer.
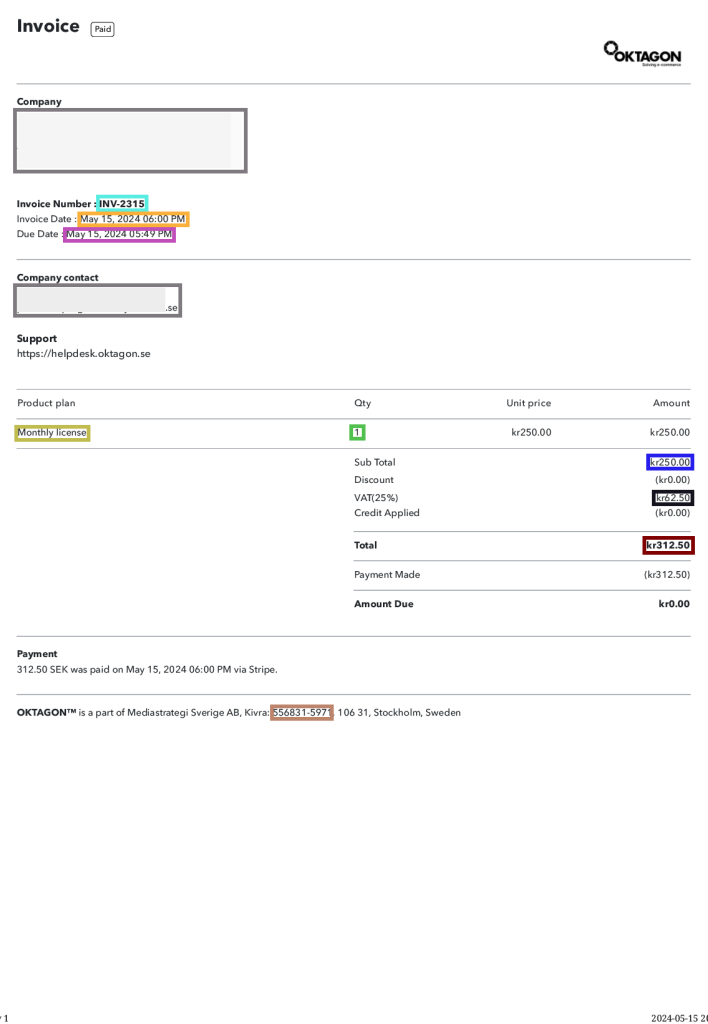
Bild 20. Layoutanalys av faktura med fakturanummer placerat på ett sätt som liknar placeringen av accessionsnummer i dialektutskriften.
När nu den modifierade klassificeringsmodellen har gjort dialektutskriftens dialogstruktur digitalt avläsbar, kan, som sagt, den precisa länkningen av de enskilda talarturerna med den faktiska inspelningen, själva ljudfilen, ta vid. Inom kort räknar vi med att kunna presentera ett urval av sådana länkade text- och tal-knippen på Isofs publika webb. På sikt planerar vi också att integrera textlänkat ljud i Isofs digitala arkivtjänst Folke.
Referenser
- Petzell, E. M. (2019). Automatisk transkribering av landsmålstext [Automatic transcription of dialect text]. Svenska landsmål och svenskt folkliv, 141(2018), 184–199.
- Petzell, E. M. (2020). Handwritten Text Recognition and Linguistic Research. I S. Reinsone, I. Skadiņa, A. Baklāne, & J. Daugavietis (Red.), Proceedings of the Digital Humanities in the Nordic Countries 5th Conference (DHN 2020), Riga, Latvia, October 21-23, 2020. : (Vol. 2612, Nummer 2612, s. 302–309). Department of Dialectology, Onomastics and Folklore Research, Gothenburg. http://ceur-ws.org/Vol-2612/
Arkivmaterial
- IFGH 941, Institutet för språk och folkminnen, Göteborg
- IFGH 1163, Institutet för språk och folkminnen, Göteborg
- IFGH 2565, Institutet för språk och folkminnen, Göteborg
- IFGH 2768, Institutet för språk och folkminnen, Göteborg
- IFGH 2991, Institutet för språk och folkminnen, Göteborg
- IFGH 4281, Institutet för språk och folkminnen, Göteborg
- IOD, gammalt nummer 27:1, Institutet för språk och folkminnen, Göteborg
Av Hanna Willdal, Erik Magnusson Petzell och Leif-Jöran Olsson