

I det första avsnittet av denna bloggserie pratade vi om den data-intensiva forskningsmetodologin och gav en övergripande bild. I nästa täckte vi texten som primärdata, och i detta avsnitt kommer vi att prata om en av många metoder som finns för att utvinna kunskap eller information ur texten, nämligen topic modelling, eller på svenska, temamodeller som producerar ett antal teman ur stora mängder text.
Vad är då temamodeller?
Temamodeller är vanliga inom digitala studier av stora textmängder och används flitigt inom digital humaniora. En temamodell är en parametrisk modell, vi måste alltså berätta för den hur många topics (hädanefter ordet tema istället för topic) som vi vill ha. [efn_note]det finns metoder som är icke-parametriska och som själva hittar det optimala antalet teman givet det primärdata som den bygger modellen över, men vanligast är LDA modeller som kräver ett specificerat antal teman.[/efn_note] Den tränar sedan upp sig och när den är klar ger den oss ett antal teman , där varje tema är en sannolikhetsfördelning över alla ord i vår vokabulär (alltså alla ord ur vårt primärdata som vi är intresserade av, vanliga val är alla substantiv).
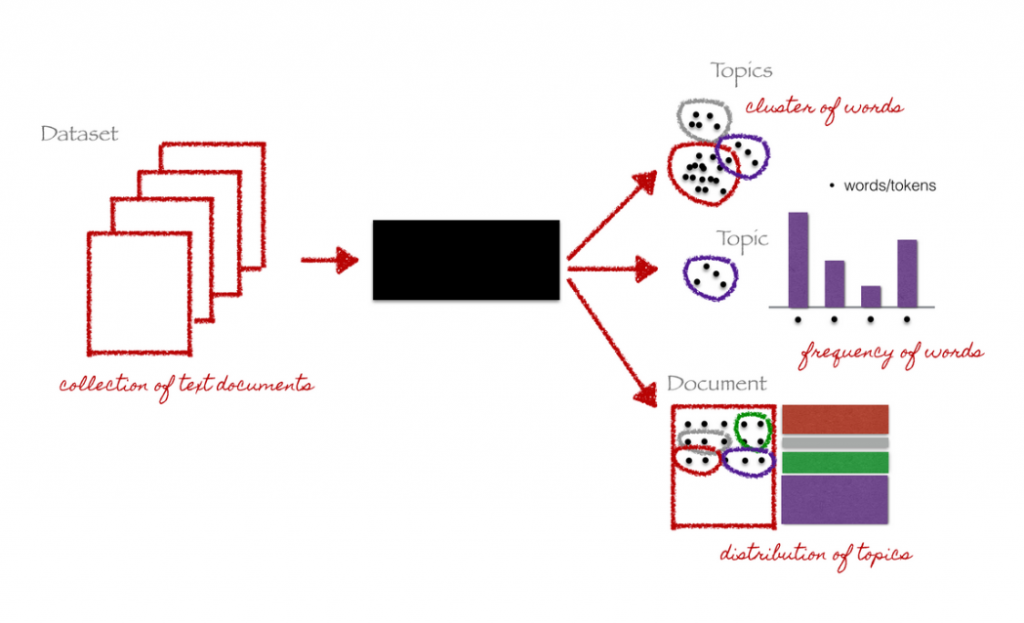
Vi börjar med en samling med dokument (våra primärdata). Dessa dokument är texter och kan vara av olika slag, nyhetsartiklar, böcker, journaltexter och så vidare. Vi ställer oss sedan den centrala frågan inom temamodellering nämligen vilka teman kan ha skapat våra dokument?
Om det inte finns naturliga uppdelningar av kortare slag (t ex nyhetsartiklar) så får vi bestämma hur långt ett enskilt ”dokument” skall vara. Vanliga val är mellan 250–1000 ord långa dokument. Vi delar alltså upp en bok i delar som är t ex 500 ord långa. Vi antar helt enkelt att hela böcker täcker många olika teman och att det därför är rimligt att dela upp en bok i mindre delar som i sin tur kan motsvara individuella teman. Skulle vi bryta upp ett långt stycke över samma tema kan ju förstås två stycken höra till samma tema.
Processen som följer sedan är ungefärligen såhär:
- Anta att vi känner till alla teman (k stycken) som skapat alla andra ord i vår korpus, förutom ord w (=koppar)
- Nu skall vi gissa vilket tema som ord w tillhör.
- Först kollar vi vilket tema som ord w (=servis, byggkonstruktion) vanligtvis tillhör
- Sen kollar vi vilka andra teman som finns i vårt dokument (om de andra orden kommer från servis, t ex fat, servering, kaffe, eller från tråd, ledning, konstruktion)
- Ett ord kan tillhöra ett tema den aldrig tillhört innan (probabilistisk model)[efn_note] En probabilistisk modell kallas ibland även sannolikhetsbaserad modell eftersom metoden innehåller ett visst mått av slump.[/efn_note]
- Därefter gissar vi vilket tema som w skall tillhöra.
- Och går igenom alla ord i vår vokabulär = en iteration.
I första steget så gissar vi, och vi delar ut teman till våra ord på måfå. Därefter går vi igenom modellen, gör uppdateringar och förbättrar steg för steg. Ord som vanligtvis används tillsammans kommer att hamna i samma tema oftare (och alltså byta ur sin första tilldelning av tema för att hamna i ett som passar bättre). Ord med flera betydelser som är relevanta för våra teman, som exemplet med koppar ovan, kan tillhöra flera teman.
- Vi slutar när det inte blir mycket ”bättre” –alltså att våra teman blir stabila och orden inte byter mellan alla teman.
- Ett tema är en sannolikhetsfördelning över alla ord tex: tema 1=(0.1, 0.5,0.2,0.4,0.6,…) vilket innebär att till tema 1 hör första ordet i vokabuläret (t ex ”a cappella” om vi sorterat i bokstavsordning) med en sannolikhet av 0.1. Alltså, om vi ser ett stycke som är genererat av tema 1 så finns det en 10% chans att vi också träffar på ordet ”a cappella” och en 50% chans att vi träffar på ord två i vår vokabulär.
- De mest sannolika orden används för att beskriva ett tema och oftast är det just de 10–25 mest sannolika orden per tema som forskarna studerar när de studerar temamodeller.
- Man kan även studera hur dokument är länkade till teman, varje dokument består av flera olika teman (i olika grad) och vi kan välja att studera de dokument som är mest relaterade till ett tema som vi är intresserade av.
- Sist men inte minst, vill man studera teman över tid har man två alternativ. Det första är en statisk modell: vi bygger en temamodell (t ex med all vår primärdata på en gång) och sedan räknar vi hur många dokument som motsvarar ett tema över tid. Det andra alternativet är att bygga en dynamisk modell: vi börjar i första tidsperioden och bygger en temamodell med texter enbart från denna tidsperiod. Sedan går vi till nästa tidsperiod och använder oss av den temamodell vi hade från förra som ett sätt att initialisera den modell vi lär oss på den andra tidsperioden och så fortsätter vi. Teman från tidsperiod 3 används som grund för teman för tidsperiod 4, osv. I de dynamiska modeller tillåter vi teman att utvecklas över tid fast vi ändå kan veta vilka teman som hör ihop.
Två viktiga egenskaper hos temamodeller:
Först är de probabilistiska modeller. Det innebär att teman ur en modell kommer att se olika ut varje gång vi kör modellen eftersom processen för att välja tema för ett ord är lite som att kasta en (k-sidig) tärning. Av alla möjliga teman (inklusive ett helt nytt tema som ordet aldrig tillhört tidigare) så väljer vi genom att kasta tärning och välja det tema som tärningen väljer. Om vi kör om modellen på precis samma primärdata kan ju vår tärning hamna på en annan sida och då väljer vi ett annat tema. Våra teman kommer då att skilja sig, lite eller mycket, mellan varje modell. Det skiljer sig även om vi skickar in våra texter i olika ordning, alltså, att mata in texterna från första januari till sista december, eller tvärt om, kommer att resultera i olika modeller.
För det andra så är temamodeller en typ av modeller som enkelt ger oss en möjlighet att hitta alla meningar eller dokument som varit med och skapat ett tema. Vi kan alltså verifiera våra teman genom att läsa (ett urval om det är väldigt många) de texter som bidragit till temat. Denna spårbarhet och verifierbarhet är det många metoder som saknar och därför kan detta ses som en av de främsta styrkorna med att använda temamodeller som verktyg för forskning.
Sist men inte minst, de ord som vi väljer att använda till vår vokabulär (ur våra primärdata) kan påverka våra texter markant.
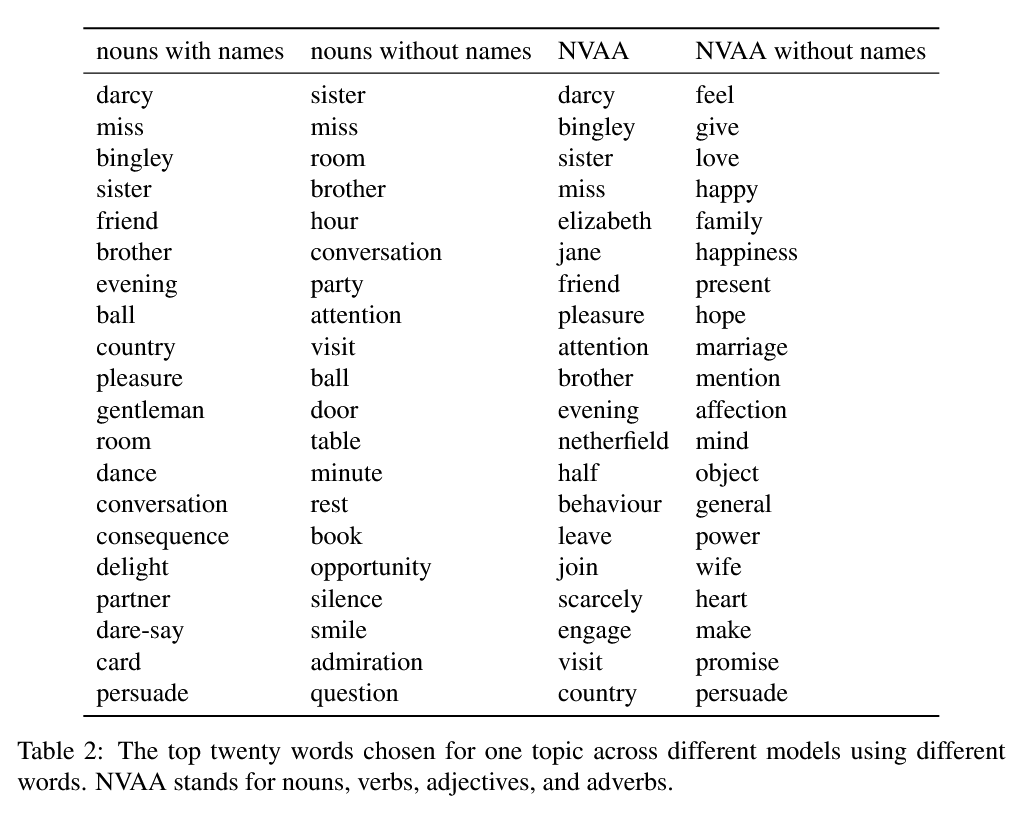
Ovan är ett exempel på en temamodell byggd på Jane Austens Stolthet och Fördom. Vi har valt ett tema och tabellen nedan visar de 20 starkaste orden för samma tema för olika val av vokabulär. I den första kolumnen har vi valt att titta på alla substantiv inklusive namn, i den andra kolumnen har vi substantiv utan namn, i den tredje har vi substantiv, verb, adjektiv och adverb (med namn) och den sista är samma som tredje kolumnen med namn exkluderade. För den sista kolumnen har vi valt ett tema på måfå eftersom det inte fanns ett tema som motsvarade de andra tre i denna modell. Det vi visar här är ungefär samma tema med eller utan namn för olika val av ord. Det som orsakar otroliga svårigheter med att svara på forskningsfrågor med hjälp av en temamodell ligger i svårigheten att bedöma vilken av dessa fyra modeller [efn_note] Det finns många fler val man kan göra som resulterar i ännu fler alternativa modeller och betänk då att varje konfiguration, med en bestämd dokumentstorlek (antal ord i dokumentet), ett k-värde som bestämmer hur många teman varje modell skall ha, samt vokabulär, så blir resultaten olika om vi kör om modellen flera gånger eftersom processen är probabilistisk.) [/efn_note]som är den ”rätta”.
Det finns metoder för att få ett mått på hur bra en temamodell är, som topic perplexity och coherence . Dessa mått berättar för oss hur väl temamodeller täcker data, och hur semantiskt lika de mest troliga orden i ett tema är. Men dessa utvärderingsmetoder svarar inte egentligen på hur den mest centrala frågan: hur väl besvarar en temamodell just vår forskningsfråga?
Slutsatser:
Temamodellering är ett kraftfullt verktyg att få en överblick över hundra, tusen, eller miljontals texter på ett enkelt sätt. Varje gång en temamodell körs resulterar den i ett resultat som skiljer sig lite från om vi kör exakt samma modell igen. Varje val vi gör (dokument storlek, antal teman, ord som inkluderas eller exkluderas ur vokabuläret) resulterar i olika modeller. Det vi bör försäkra oss om när det gäller resultaten är:
- att temamodellen är meningsfull och representativ för den primärdata vi modellerar,
- att vi använder oss av resultaten på ett meningsfullt sätt när vi skall besvara vår forskningsfråga. Detta är viktigt eftersom temamodeller fångar en viss typ av information ur text. Denna information kan vara användbar för vissa typer av frågor, men inte för andra, samt
- att vi redovisar hur vi går från ett komplext resultat (som ju trots allt ett flertal sannolikhetsfördelningar är) till ett svar på vår forskningsfråga.
Den sista delen är av högsta vikt för att andra skall kunna reproducera våra resultat och jämföra mellan modeller och metoder.
Vill du veta mer om vilka aspekter av en data-intensiv forskningsmetodologi som är problematiska eller vilka styrkor den har kan du läsa mer i vår artikel: The Strengths and Pitfalls of Large-Scale Text Mining for Literary Studies . Jag som skriver detta inlägg heter Nina Tahmasebi och är docent inom Språkteknologi och en data scientist, en dataforskare, med över 12 års erfarenhet av storskalig textanalys och kunskapsutvinning. Detta blogginlägg kommer att följas upp med ytterligare några inlägg som tar upp olika aspekter av den data-intensiva processen. Några videor från en studiecirkel på samma tema finns här.