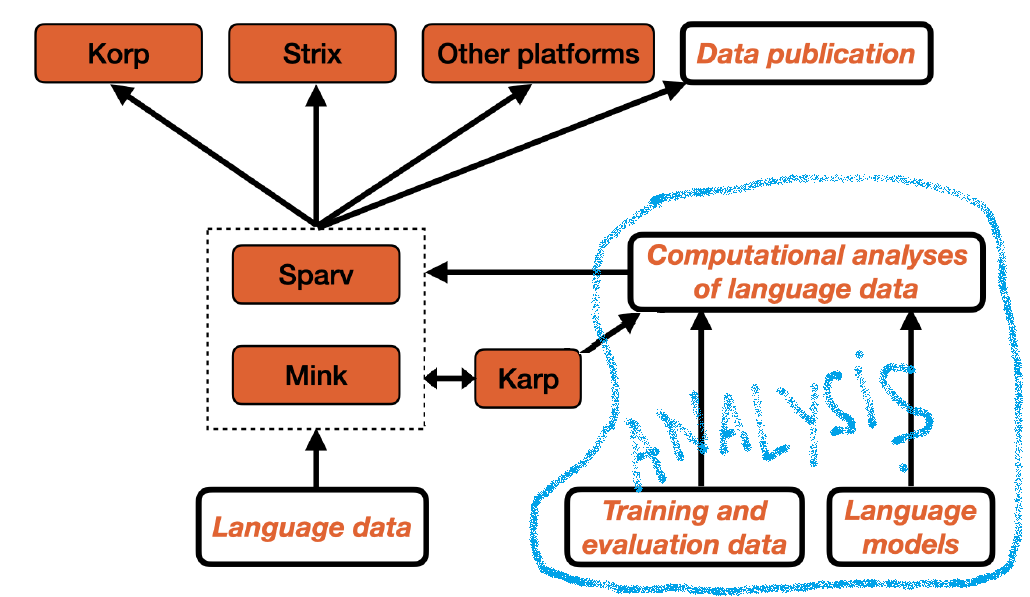



Within the Cassandra project we are using Korp to analyze numerous instances of language change: not one, not two, but dozens (and in the future, potentially hundreds). At this scale, it is impossible to perform searches (and process their results) manually. Fortunately, Korp has an API that makes an automatization of this process possible.
This post is based on joint work with Gerlof Bouma. Illustrations by Jan and Julija.
Here's a sad story (it's fictional, but sad nonetheless).
We at Språkbanken Text have just released a new corpus of native (L1) and non-native (L2) speech in four languages: English, Spanish, French and Italian. The corpus contains more than 170 million words produced by more than 97 thousand speakers (size varies a lot across the four languages, though).

Ord kan förändra sina betydelser. Man behöver inte en doktorgrad i språkvetenskap för att upptäcka att grym i (1) betyder inte samma sak som i (2).