

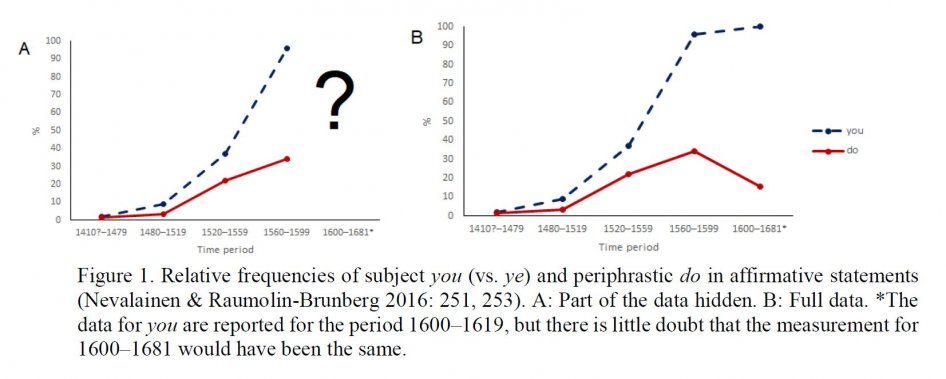
Imagine that someone named Cassandra is looking at Fig. 1A and trying to guess what is hidden by the question marks. She does not know the answer, since she does not speak Modern English, but she knows the history of England well enough to be certain that, for instance, no royal decree banning the usage of you has been passed in 1600. She guesses that the dotted blue line of you will reach 100%, while the solid red line of do will end up around 45%.
Looking at Fig. 1B, we can see that Cassandra's prediction was correct for you, but not for periphrastic do. Allow Cassandra access to large language corpora and rich sociocultural data, and actually replace "Cassandra" with "modern language science". Will the predictions be better? There is an influential line of thinking that they will not and that they actually do not have to.
Nonetheless, if, given a wealth of data, our theories still cannot "predict", to what extent can we claim that our theories actually explain something about language change? The skepticism is hypothetical: we do not know the predictive power of linguistic theories (it can be very high).
The main purpose of this project (henceforth labelled "Cassandra") is to perform a rigorous quantitative test of the explanatory power of theories about language change by measuring their predictive accuracy. We will achieve this by using very large corpora of Swedish social media that contain linguistically annotated data for the last 20 years. The corpora were created and are maintained at Språkbanken Text. To give a few examples of changes that can be captured within these data: the emergence of neologisms (näthat 'net hate'); the emergence of new meanings (fett 'fat' used as intensifier, cf. fett stark 'very strong'); dramatic changes in frequency (the spread of hen as a gender-neutral pronoun); changes in the distribution of word forms (the increased usage of the singular form förälder 'parent'). We will also explore whether changes beyond the word level, such as shifts in the distribution of word order frequencies or other syntactic patterns, may be uncovered in the short time span of our corpus.
We will calculate diachronic trajectories of these and other phenomena, split each trajectory into "seen" and "unseen" parts and try to predict the unseen part from the seen. Predictions will rely on existing hypotheses about the mechanisms of change and use both linguistic and social information (e.g., the structure of the social network that the users are part of). We will also perform a more ambitious test and make predictions about future changes in this register of Swedish.
Apart from theoretical results, Cassandra will yield new resources and methodological advances. The resources we create (the corpora enriched with information about social-network structure and language change) will facilitate access to social-media data (an important part of cultural heritage and part of digital media). The methods we develop will be relevant for all scholars or practitioners who are interested in how changes spread across society.
Logo by Tanja Russita

