

NODALIDA workshop, Gothenburg, Sweden, 22 May, 2017
ACL Proceedings are now online!
Proceedings from LiU Press are now available!
Thank you all for a wonderful workshop!
Some workshop pictures

Elena Volodina opens the workshop

Xiaobin Chen is presenting work on a syntactical workbench

Johannes Graën and Gerold Schneider are "crossing the border" - twice ;-)
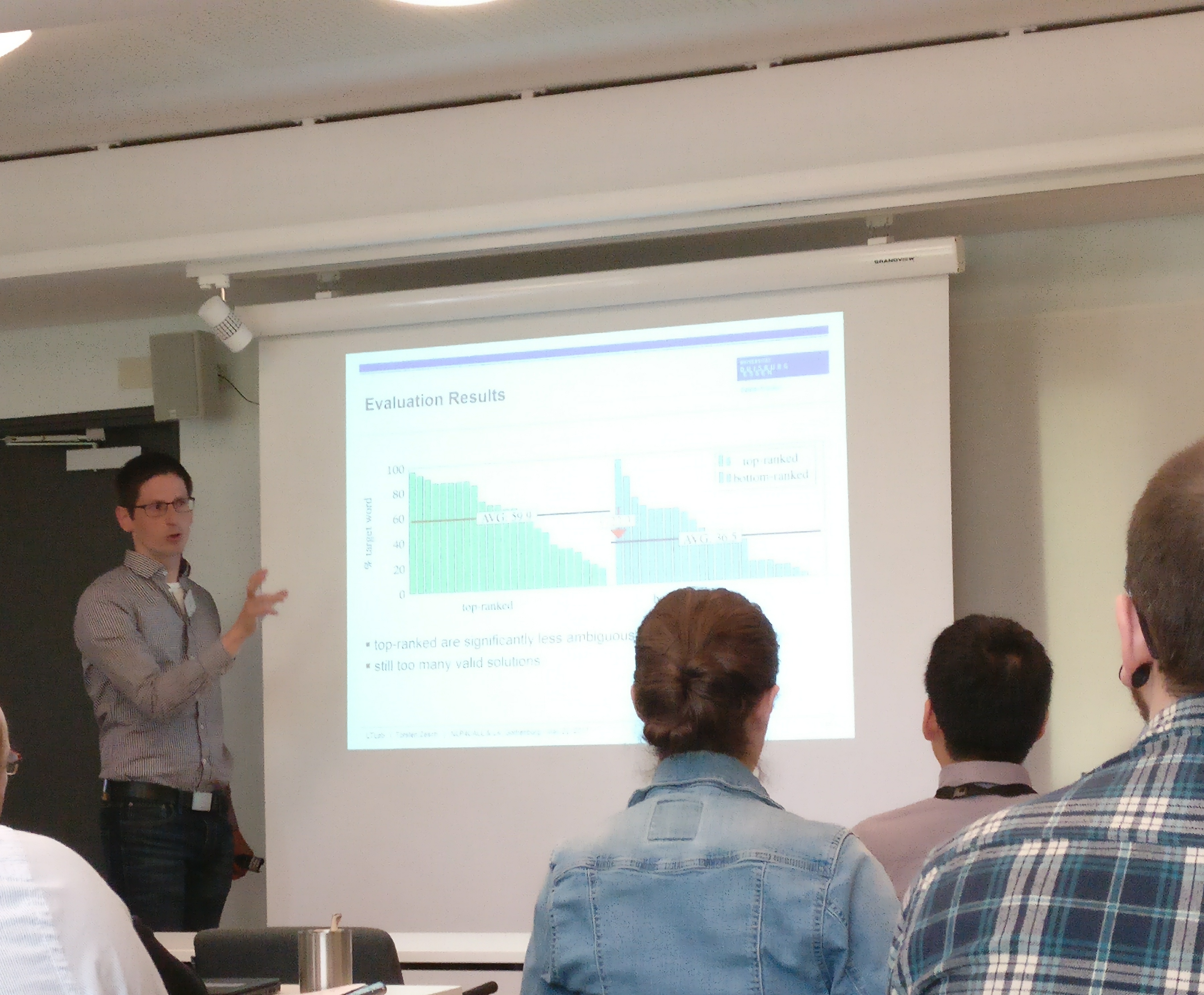
Torsten Zesch gives an invited speech on automatic gap-fill exercises

Anisia Katinskaia talks on endangered languages and their support

Ramon Ziai and Björn Rudzewitz present work on a web-based workbook for English

Sara Stymne describes their experiment on error-annotating Swedish learner texts

Heli Uibo discusses their platform for supporting minority languages

Bente Ailin Svendsen gives an invited talk on The Dynamics of Citizen Science in Exploring Language Diversity

A well-deserved afterwork(shop)
ICALL-related mailing lists
There are two mailing lists that spread ICALL-relevant information: one run by EuroCALL/CALICO SIG-ICALL group (nlpcall@artsservices.uwaterloo.ca // nlpcall@watarts.uwaterloo.ca) and the other one run by BEA-workshop organizers (bea.nlp.workshop@gmail.com). We encourage you to join them to be updated of the events, publications and discussions in the area
- To join EuroCALL/CALICO list, contact Mathias Schulze mschulze at uwaterloo dot ca . You can freely write to the EuroCALL/CALICO list when you want to disseminate some call for papers/information or ask questions.
- To join BEA-list, contact Joel Tetreault tetreaul at gmail dot com . BEA-mailing list spreads information in a digest form approx 4 times a year.
Venue
The workshop will be held in the Room "South America", at Conference Centre Wallenberg, centrally located in Gothenburg:
Street address: Medicinaregatan 20A, 413 90 Gothenburg, Sweden. [OpenStreetMap, Google Maps]
Find your way to the conference venue
Registration information
At least one author of the accepted papers should be registered for the workshop. Information on registration can be found here. Welcome to the workshop!
Program
Room: South America
| Time | Program point. |
| Morning session 1. Chair: Kristina Nilsson Björkenstam | |
| 9.00 - 9.30 | Opening. Elena Volodina [slides] |
| 9.30 - 10.00 | Allison Adams and Sara Stymne. Learning with Learner Corpora: using the TLE for Native Language Identification. [pdf] [slides] |
| 10.00 - 10.30 | Coffee break |
| Morning session 2. Chair: Lars Borin | |
| 10.30 - 11.00 | Xiaobin Chen and Detmar Meurers. Developmental Benchmark of Syntactic Complexity. [pdf] [slides] |
| 11.00 - 11.30 | Johannes Graën and Gerold Schneider. Crossing the Border Twice: Reimporting Prepositions to Alleviate L1-Specific Transfer Errors. [pdf] [slides] |
| 11.30 - 12.20 | Invited talk by Torsten Zesch: Automatically ____ gap-fill exercise items. [slides] |
| 12.30 - 13.30 | Lunch |
| Afternoon session 1. Chair: Elena Volodina | |
| 13.30 - 14.00 | Anisia Katinskaia, Roman Yangarber and Javad Nouri. Tools for Language Learning and Supporting Endangered Languages. [pdf] [slides] |
| 14.00 - 14.30 | Björn Rudzewitz, Ramon Ziai, Kordula De Kuthy and Detmar Meurers. Developing A Web-based Workbook for English Supporting the Interaction of Students and Teachers. [pdf] [slides] |
| 14.30 - 15.00 | Sara Stymne, Eva Pettersson, Beáta Megyesi and Anne Palmér. Annotating Errors in Student Texts: First Experiences and Experiments. [pdf] [slides] |
| 15.00 - 15.30 | Coffee break |
| Afternoon session 2. Chair: GintarÄ GrigonytÄ | |
| 15.30 - 16.00 | Heli Uibo, Jack Rueter and Sulev Iva. Building and using language resources and infrastructure to develop e-learning programs for a minority language. [pdf] [slides] |
| 16.00 - 16.50 | Invited talk by Bente Ailin Svendsen: The Dynamics of Citizen Science in Exploring Language Diversity. [slides] |
| 16.50 - 17.00 | Closing |
Invited speakers
This year we have the pleasure to welcome two invited speakers:
Torsten Zesch, University of Duisburg-Essen
-
Bio:Torsten Zesch leads the Language Technology Lab at University of Duisburg-Essen, Germany. He holds a doctoral degree in Computer Science from Technische Universität Darmstadt and has worked as a substitute professor at the German Institute for International Pedagogical Research. His research interests include the processing of non-standard, error-prone language as found in social media and learner language. He also focuses on exercise generation for computer-assisted language learning and automatic assessment of free-text answers and essays.
-
Talk: Automatically ____ gap-fill exercise items.
-
The talk will give an overview about our work on automatically generating and scoring gap-fill exercise items. This will cover our early experiments on trying to find low-ambiguity contexts, the follow-up work on generating challenging distractors, and finally the recently introduced gap-fill bundles.
Bente Ailin Svendsen, University of Oslo
-
Bio: Bente Ailin Svendsen is Professor of Second Language Acquisition and Scandinavian Linguistics. She initiated and co-developed MultiLing Multilingualism in Society across the Lifespan, a Center of Excellence funded by the Research Council of Norway (RCN), where she was the Deputy Director 2013-2015. She has carried out research on multilingual socialisation, competence and use among children and adults; and on linguistic practices and identity constructions among young people in multilingual urban spaces. Her publications include the book Language, Youth and Identity in the 21st Century. Linguistic Practices across Urban Spaces (co-edited with Jacomine Nortier, Cambridge UP, 2015), Multilingual Urban Scandinavia: New Linguistic Practices (co-edited with Pia Quist, Multilingual Matters, 2010), as well as articles in the European Journal of Applied Linguistics, International Journal of Bilingualism and Nordic and Norwegian journals and books.
-
Talk: The Dynamics of Citizen Science in Exploring Language Diversity.
-
The objective of this paper is to explore the dynamics of citizen science (CS) in sociolinguistics, i.e. the involvement of non-professionals in doing sociolinguistic research, coined as Citizen Sociolinguistics (Rymes and Leone 2014, Svendsen, pending for review). In 2014, Norwegian pupils in all grades were invited to become citizen scientists through a national research campaign. Data from 4500 pupils reveal a vast linguistic diversity, an eagerness to learn languages, and a widespread use of English on a daily basis. The results, however, reflect prevailing hierarchical language regimes, firstly in the selection of specific ‘foreign’ languages offered and the desire of pupils to learn them, and secondly in the fact that the pupils’ home languages are not actively used in the classroom. This paper argues that one of the main advantages of Citizen Sociolinguistics is its wide-reaching potential and that it represents a method suited for collecting big data sets. Secondly, it is argued, based on a media analysis of the above CS-study, that CS has a potential to increase linguistic awareness and thus stimulating linguistic stewardship. However, CS raises some challenges for sociolinguistic research, ethically, as well as ontologically and epistemologically: what do CS-data represent and what claims can be made from them? Epistemologically, with a CS methodology, we are decentralising authority on who holds legitimate knowledge about language. Citizen Sociolinguistics is about opening the dialogue between ‘the academy’ and the ‘citizens’, it stimulates public engagement and it has a potential to advance the social impact of sociolinguistics.
References
- Rymes, Betsy and Andrea R. Leone. 2014. Citizen sociolinguistics: A new media methodology for understanding language and social life. Working Papers in Educational Linguistics 29(2): 25–43.
- Svendsen, Bente Ailin, pending for review. The Dynamics of Citizen Science in Sociolinguistics. Journal of Sociolinguistics.
- Svendsen, Bente Ailin, Else Ryen and Kristin Vold Lexander. 2015. Rapport fra Forskningskampanjen 2014: Ta tempen på språket! [Report on the Research Campaign 2014: Taking the temperature of language!]. Oslo: Norwegian Research Council.
Description of the workshop
For the second year in a row we are bringing two related themes of NLP for CALL and NLP for LA together. The goal of the joint workshop is to provide a meeting place for researchers working on language learning issues including both empirical and experimental studies and NLP-based applications.
The theme on Natural Language Processing (NLP) for Computer-Assisted Language Learning (NLP4CALL) iis a meeting place for researchers working on the integration of Natural Language Processing and Speech Technologies in CALL systems and exploring the theoretical and methodological issues arising in this connection.
The intersection of Natural Language Processing and Speech/Dialogue Technology with Computer-Assisted Language Learning (CALL) brings “understanding” of language to CALL tools, thus making CALL intelligent. This fact has given the name for this area of research – Intelligent CALL, ICALL. As the definition suggests, apart from having excellent knowledge of Natural Language Processing and/or Speech/Dialogue Technology, ICALL researchers need good insights into the second language acquisition (SLA) theories and practices, as well as knowledge of second language pedagogy and didactics. This workshop invites therefore all ICALL-relevant research, including studies where NLP-enriched tools are used for testing SLA and pedagogical theories, and vice versa, where SLA theories/pedagogical practices are modeled in ICALL tools.
The workshop on Natural Language Processing (NLP) for Research in Language Acquisition (NLP4LA) broadens the scope of this year’s joint workshop to also include theoretical, empirical, and experimental investigation of first, second and bilingual language acquisition.
We believe that this field will benefit from collaboration between the NLP, linguistics, psychology and cognitive science communities. The workshop is targeted at anyone interested in the relevance of computational techniques for first, second and bilingual language acquisition. Therefore, our aim is to bring together researchers from different fields with a shared interest in language acquisition.
The NLP4CALL&LA workshop series is aimed at bringing together competences from these areas for sharing experiences and brainstorming the future of the field.
For the two tracks we welcome papers:
-
that describe research directly aimed at ICALL
-
that demonstrate actual or discuss the potential use of existing Speech Technologies, NLP tools or resources for language learning
-
that describe the ongoing development of resources and tools with potential usage in ICALL, either directly in interactive applications, or indirectly in materials, application or curriculum development, e.g. collecting and annotating ICALL-relevant corpora; developing tools and algorithms for readability analysis, selecting optimal corpus examples, etc.
-
that discuss challenges and/or research agenda for ICALL
-
that describe empirical studies on language learner data
-
that describe computational models of first, second and bilingual language acquisition
-
that describe empirical or experimental studies, or computational models of various aspects of language and their effect in language comprehension and acquisition
-
that demonstrate actual or discuss the potential use of Speech Technologies, NLP tools or resources for investigating language acquisition
-
that describe psycholinguistic and socio-linguistic investigations on first, second and bilingual language acquisition
We especially invite submissions describing the above-mentioned themes for the Nordic languages; and papers that focus on different age groups, cultures, and language variation. We are also interested in software demonstrations.
Submission information
We will be using Nodalida 2017 template for the workshop this year. Authors are invited to submit long papers (8-12 pages) alternatively short papers (4-7 pages), page count not including references. Only pdf files will be accepted. Submissions will be managed through the electronic conference management system EasyChair. Final camera-ready versions of accepted papers will be given an additional page to address reviewer comments.
Papers should describe original unpublished work or work-in-progress. Every paper will be reviewed by at least 2 members of the program committee. As reviewing will be blind, please ensure that papers are anonymous. Self-references that reveal the author's identity, e.g., "We previously showed (Smith, 1991) ...", should be avoided. Instead, use citations such as "Smith previously showed (Smith, 1991) ...". Submissions will be judged on appropriateness, clarity, originality/innovativeness, correctness/soundness, meaningful comparison, significance and impact of ideas or results.
All accepted papers will be collected into a proceedings volume to be submitted for publication in the NEALT Proceeding Series (Linköping Electronic Conference Proceedings) and, additionally, double-published through ACL anthology, following experiences from previous workshops, e.g. the 3rd NLP4CALL.
Important dates:
- 16 January, Monday: first call for papers
- 13 February, Monday: second call for papers
- 6 March, Monday: third call for papers
- 20 March, Monday: paper submission deadline (short and long)
- 6 April, Thursday: notification of acceptance
- 13 April, Thursday: camera-ready papers for publication
- 4 May, Thursday: call for participation
- 22 May, Monday: workshop date
Program committee:
- Lars Ahrenberg, Linköping University, Sweden
- Florencia Alam, CONICET, Argentina
- Christina Bergmann, Centre National de la Recherche Scientifique, France
- Eckhard Bick, University of Southern Denmark, Denmark
- Lars Borin, University of Gothenburg, Sweden
- Antonio Branco, University of Lisboa, Portugal
- Jill Burstein, Educational Testing Service, USA
- Piet Desmet, KU Leuven Kulak, Belgium
- Simon Dobnik, University of Gothenburg, Sweden
- Thomas Francois, UCLouvain, Belgium
- Gintare Grigonyte, Stockholm University, Sweden
- Anna Gudmundsson, Stockholm University, Sweden
- Björn Hammarberg, Stockholm University, Sweden
- Katarina Heimann Mühlenbock, DART, Sahlgrenska Universitetssjukhuset, Sweden
- Sofie Johansson, University of Gothenburg, Sweden
- Chigusa Kurumada, University of Rochester, USA
- Peter Ljunglöf, Chalmers Tekniska Högskolan, Sweden
- Ellen Marklund, Stockholm University, Sweden
- Detmar Meurers, University of Tübingen, Germany
- Kristina Nilsson Björkenstam, Stockholm University, Sweden
- John K. Pate, The University at Buffalo, USA
- Martí Quixal, Univeristat Oberta de Catalunya, Spain
- Lena Renner, Stockholm University, Sweden
- Gerold Schneider, University of Konstanz, Germany
- Mathias Schulze, University of Waterloo, Canada
- Philip Shaw, Stockholm University, Sweden
- Jennifer Spenader, University of Groningen, Netherlands
- Sofia Strömbergsson, Karolinska Institutet, Sweden
- Joel Tetreault, Yahoo! Labs, USA
- Cornelia Tschichold, Swansea University, UK
- Francis Tyers, The Arctic University of Norway, Norway
- Sowmya Vajjala, Iowa State University, US
- Paul Vogt, Tilburg University, Netherlands
- Elena Volodina, University of Gothenburg, Sweden
- Torsten Zesch, University of Duisburg-Essen, Germany
- Robert Östling, Stockholm University, Sweden
Workshop organizers
- Elena Volodina, Språkbanken, Department of Swedish, University of Gothenburg; elena dot volodina at svenska dot gu dot se (Organizing chair)
- Lars Borin, Språkbanken, Department of Swedish, University of Gothenburg; lars dot borin at svenska dot gu dot se
- Ildikó Pilán, Språkbanken, Department of Swedish, University of Gothenburg; ildiko dot pilan at svenska dot gu dot se
- Gintare Grigonyte, Department of Linguistics, Stockholm Univeristy
- Kristina Nilsson Björkenstam, Department of Linguistics, Stockholm Univeristy
This workshop follows a series of workshops on NLP for CALL organized by a Special Interest Group in Intelligent Computer-Assisted Language Learning (SIG-ICALL of NEALT). The workshop series has previously been financed by the Center for Language Technology at the University of Gothenburg.
We intend to continue this workshop series, which up to date has been the only ICALL-relevant recurring event based in the Nordic countries. Our intention is to co-locate the workshop series with the two major LT events in Scandinavia, SLTC and Nodalida, thus making this workshop an annual event. Through this workshop, we intend to profile ICALL research in Nordic countries and to provide a dissemination venue for researchers active in this area.
Related links
- Joint 5th workshop on NLP for CALL and 1st workshop on NLP for Research on Language Acquisition
- 4th workshop on NLP for CALL
- 3rd workshop on NLP for CALL
- 2nd workshop on NLP for CALL
- 1st workshop on NLP for CALL
- SIG-ICALL, NEALT
For NLP4CALL inquiries, please email Elena Volodina (elena dot volodina at svenska dot gu dot se)
For NLP4LA inquiries, please email Gintare Grigonyte (gintare at ling dot su dot se)