

När vi tänker på ord så tänker vi oftast på enheter som i text omges av blanksteg (mellanrum): 'huset', 'superstor', 'bloggade'. De flesta skulle nog säga att 'idag' är ett ord, men hur är det om vi skriver det (också rättstavat) 'i dag' då? 'Mont Blanc-tunneln'? 'Röda blodkroppar'? I det här blogginlägget tänkte jag prata om ord som innehåller mellanrum och flerordsuttryck, och hur man kan analysera dem i en korpus.
Om vi ska annotera en text, alltså märka upp den med olika sorters lingvistisk information som ordklasser och syntaktiska funktioner, måste vi bestämma oss för vad ett ord är. Ordet blir (ofta) vår grundläggande enhet. För många språkteknologer är definitionen "ett ord är en enhet tecken som normalt omges av mellanslag" tillräckligt bra. Den är också lätt att använda automatiskt. Man behöver bara identifiera förkortningar (där punkten är en del av ordet) och separera övriga skiljetecken från ordenheterna med hjälp av mellanrum. Sedan delar man upp texten vid varje mellanrum och får då ordenheter (token). Nackdelen med en sådan metod är förstås att ord som 'Mont Blanc-tunneln' då består av orden 'Mont' och 'Blanc-tunneln' (alternativ 'Mont' och 'Blanc' och '-' och 'tunneln', vilket möjligen är en bättre lösning). Och att 'idag' ibland är ett ord och ibland två ('i' och 'dag').
Trädbanken Eukalyptus innehåller flera oika sorters texter, som har annoterats manuellt med ordklasser, morfologisk information, ordbetydelser, samt syntaktiska fraser och funktioner. Den avviker från de flesta andra korpusar genom att vi tillåter blanksteg inuti ord. Vi låter alltså 'Mont Blanc-tunneln' behandlas som ett enda ord.
Nackdelen med denna lösning är att många av de automatiska verktyg som används för att hantera språkligt material inte fungerar med token som innehåller mellanslag. Det är delvis en ren programmeringsfråga, att de som skapar verktyg ibland förutsätter att ord inte innehåller mellanslag och låter det påverka hur programmet fungerar. Men det är delvis också en fråga om hur komplext programmet kan vara. De flesta program för att analysera text är uppbyggda steg för steg. Först gör vi segmentering, där vi delar in texten i ord och meningar. Sedan märker vi ut ordklasser. Därefter bygger vi upp den syntaktiska strukturen baserat på ordklasserna. Om vi då stöter på uttrycket 'i går' kan vi under tokeniseringssteget inte avgöra om det ska vara ett ord, som i 'Jag såg henne i går', eller två, som i 'Mannen som hon struntade i går där borta', utan behöver hålla flera alternativ i minnet tills vi kommer till ett senare steg. För att både behålla den mer språkligt rimliga hanteringen av ordenheter och samtidigt kunna använda befintliga verktyg för språkanalys planerar vi att också göra Eukalyptus tillgänglig i en version som inte innehåller några mellanslag i ord.
Utöver att vi i Eukalyptus tillåter ord som innehåller blanksteg så använder vi ytterligare ett sätt att markera ordenheter som består av flera delar, så kallade flerordsuttryck. Flerordsuttryck är ord som vanligen förekommer tillsammans, t ex 'på grund av', och partikelverb som 'komma hem'. De är också uttryck som ofta har en betydelse som inte kan förstås direkt utifrån de ingående ordens egenskaper, t ex 'få blodad tand' och 'ana ugglor i mossen'. Tack vare att Språkbankens centrala lexikon för modernt svenskt skriftspråk, SALDO (Svenskt Associationslexikon version 2), innehåller många flerordsuttryck, har vi också möjlighet att automatiskt identifiera en hel del av dem.
Man kan säga att flerordingar tillhör både den lexikala och den syntaktiska domänen. Annoteringsmodellen i Eukalyptus låter oss binda ihop delarna i flerordsuttryck till en enhet, som kan kategoriseras med hjälp av samma uppsättning kategorier som ord (d.v.s. ordklasser). Samtidigt kan delarna i ett flerordsuttryck i många fall analyseras syntaktiskt som vilka ord som helst. Vi skiljer därför på två typer av flerordingar i annoteringen.
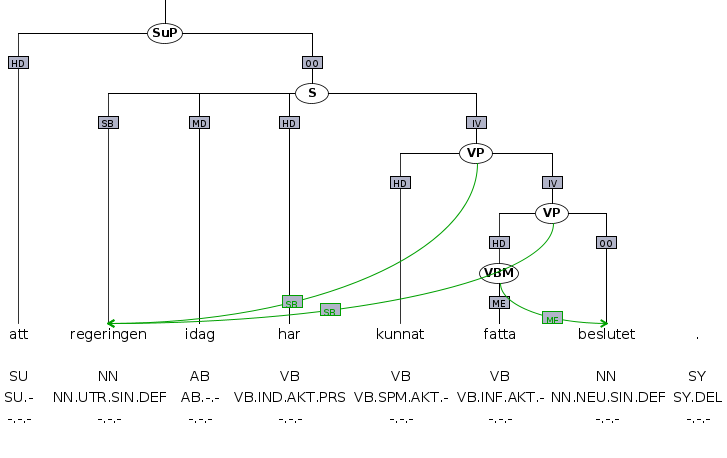
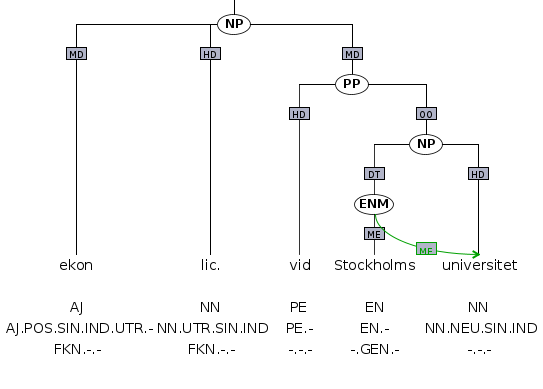
Den ena typen är uttryck som kan analyseras enligt den vanliga syntaktiska modellen. I fallet 'fatta beslut' är verbet 'fatta' huvud (HD) i en verbfras (VP) med 'beslut' som objekt (OO). Samtidigt är 'fatta beslut' ett flerordsverb (VBM): verbet 'fatta' har en mycket svag betydelse i flerordsuttrycket eftersom det inte betyder att fysiskt gripa tag i något eller att förstå och kombinationen av de två orden tillsammans är också betydligt vanligare än om man byter ut ett av orden (visserligen förekommer 'ta beslut', men sällan 'bestämma beslut' eller 'göra beslut'). Delarna i flerordingen kopplas till flerordsetiketten med s.k. sekundärkanter, som i exempelbilden markeras i grönt med funktionsetiketten ME för flerordsenhet. Ett flerordsnamn (ENM) som 'Stockholms universitet' ser syntaktiskt ut som en nominalfras (NP) med en determinerare (DT) och ett huvud.
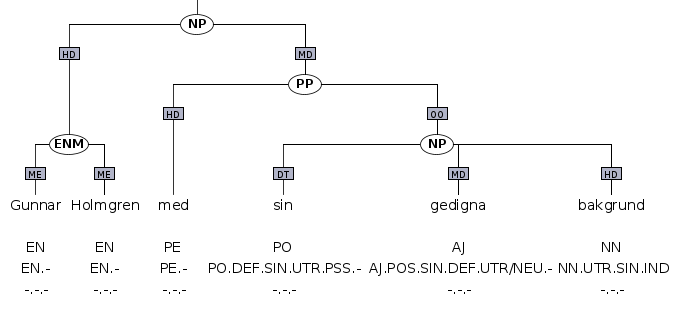
Den andra typen är flerordingar som inte kan analyseras på traditionellt sätt, eller där den interna strukturen är ointressant för den syntaktiska beskrivningen. För personnamn är det inte relevant att använda den vanliga syntaktiska beskrivningen för att definiera relationen mellan förnamn och efternamn, utan de följer sin egen logik för hur förnamn och efternamn ser ut på svenska. Förnamn och efternamn kopplas därför samman till ett flerordsnamn (ENM). Detta görs direkt utan sekundärkanter. Flerordsfrasen används därefter som helhet direkt i den syntaktiska strukturen.
En viktig poäng med detta sätt att hantera flerordingar är att det inte tillför någon information om flerordingarna, som t ex till vilken grad flerordsuttrycken är kompositionella, dvs kan förstås utifrån sina beståndsdelar. Sådant har t ex våra kollegor i Stockholm (Kurfalı m fl 2020) undersökt närmare för svenska. Däremot låter vår modell oss hantera flerordsuttryck i annoteringen av en trädbank.
Sammantaget gör dessa två lösningar -- att vi tillåter mellanslag i ord och att vi enkelt kan knyta samman flerordsuttryck -- att vi på ett enkelt sätt kan hantera ordenheter som består av flera delar. Och det är en stor fördel inte bara för ord som 'i dag' och 'Mont Blanc-tunneln', utan också när man vill analysera språket i bloggar och diskussionsforum, där man frekvent bryter mot de traditionella reglerna kring vad som skrivs ihop och vad som skrivs isär.
Referenser och mer att läsa
Murathan Kurfalı, Robert Östling, Johan Sjons, and Mats Wirén. A multi-word expression dataset for Swedish. In Proceedings of The 12th Language Resources and Evaluation Conference, 2020.
En utförligare beskrivning av vår hantering av flerordsuttryck i Eukalyptus kan man hitta här:
Yvonne Adesam, Gerlof Bouma, and Richard Johansson. Multiwords, word senses and multiword senses in the Eukalyptus treebank of written Swedish. In Proceedings of TLT, 2015.
Tidigare relaterade blogginlägg:
Om ordklasser för svenska språket
En syntaktisk beskrivningsmodell för modern svensk text