

Towards a knowledge-based culturomics
The project Towards a knowledge-based culturomics is supported by a framework grant from the Swedish Research Council (2012-2016; dnr 2012-5738). It is a collaboration between three research groups in language technology and computer science:
- Språkbanken (the Swedish Language Bank), University of Gothenburg
- The language technology research group in the Department of Computer Science, Lund University
- The research group on algorithms and machine learning in the Department of Computer Science and Engineering, Chalmers University of Technology
Aims
Recently, scholars have begun to draw on the massive amounts of text data made available through Google's large-scale book digitization project in order to track the development of cultural concepts and words over the last two centuries, announcing a new field of research named "culturomics" by its originators.
However, these initial studies have been (rightly) criticized for not referring to relevant work in linguistics and language technology. Nevertheless, the basic premise of this endeavor is eminently timely. Even if we restrict ourselves to the written language, vast amounts of new Swedish text are produced every year and older texts are being digitized apace in cultural heritage projects. This abundance of text contains enormous riches of information. However, the volumes of Swedish text available in digital form have grown far beyond the capacity of even the the fastest reader, leaving automated semantic processing of the texts as the only realistic option for accessing and using this information.
The main aim of this research program is to advance the state of the art in language technology resources and methods for semantic processing of Swedish text, in order to provide researchers and others with more sophisticated tools for working with the information contained in large volumes of digitized text, e.g., by being able to correlate and compare the content of texts and text passages on a large scale.
The project will focus on the theoretical and methodological advancement of the state of the art in extracting and correlating information from large volumes of Swedish text using a combination of knowledge-based and statistical methods. One central aim of this project will be to develop methodology and applications in support of research in disciplines where text is an important primary research data source, primarily the humanities and social sciences (HSS).
The innovative core of the project will be the exploration of how to best combine knowledge-rich but sometimes resource-consuming LT processing with statistical machine learning and data mining approaches. In all likelihood this will involve a good deal of interleaving. One example: Topic models based on documents as bags-of-words could be used for preliminary selection of document sets to be more deeply processed, the results of the semantic processing subsequently being fed into other machine-learning modules, back to the topic models in order to refine the selection, or for processing by logical reasoners. In order to guide this development, visual analytics will be invaluable. If results of processing can be represented as graphs – which is often a natural representation format for linguistic phenomena in texts or text collections– a whole battery of network analysis tools will be at the researcher’s disposal. We can use them to find clusters of similar documents or entities, pinpoint those documents that were most influential to the rest, or perform any of a number of other tasks designed for network analysis.
Sentiment Analysis
There is an increasing demand for multilingual sentiment analysis, and most work on sentiment lexicons is still carried out based on English lexicons like WordNet. In addition, many of the non-English sentiment lexicons that do exist have been compiled by (machine) translation from English resources, thereby arguably obscuring possible language-specific characteristics of sentiment-loaded vocabulary. We create a gold standard for a Swedish sentiment lexicon, using Best-Worst Scaling with human annotators, and we use this gold standard to test several methods to create a native Swedish sentiment lexicon (SenSALDO), using resource-based methods based on SALDO, and corpus-based methods based on word embeddings.
Currently, we are working on the construction of a sentence-level sentiment analysis engine using SenSALDO and syntactic analysis, the creation of a very large gold standard for aspect-based sentiment analysis, and an aspect-based sentiment analysis engine trained on this gold standard.
Analysis of political stance
We are also working on analysis and representation of political stance, using open data from the Swedish Parliament combined with language technology and topic modelling. This approach has similarities and can complement aspect-based sentiment analysis, but differs insofar linguistic features are used only for the detection of topics/aspects, but sentiment is extracted from extra-linguistic features.
Exploring language over time
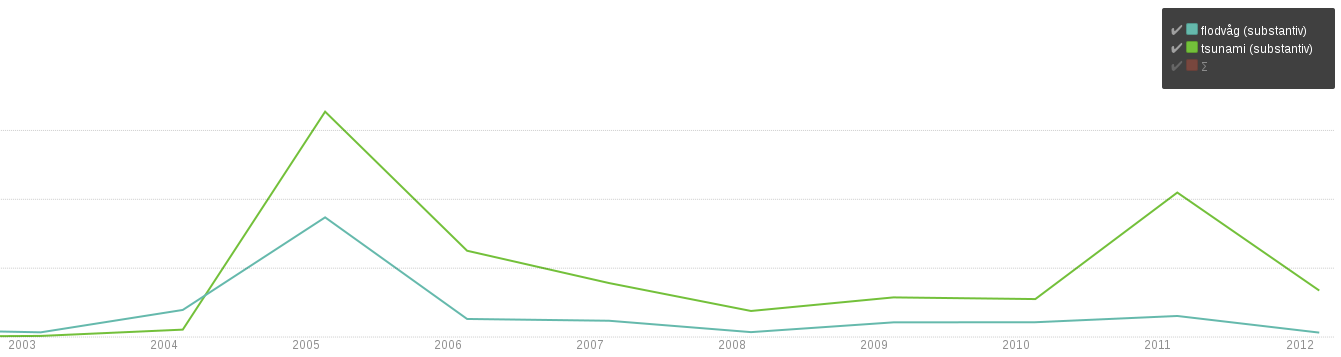
The following figures show the kind of results that emerge directly from a linguistically annotated text material available through Språkbanken’s general corpus infrastructure. Unlike the culturomics work referred to earlier, the diagrams show the distribution of the lexemes (lexicon words) tsunami and flodvåg in a newspaper material covering the years 2001–2011, including all inflectional forms and all compounds containing these words. This is made possible by the lexical analysis tools based on handcrafted resources used for annotating Språkbanken’s corpora.
Text processing in social media and historical texts
In many text processing tasks, features based on words are crucial. While it may be useful to preprocess the words carefully, e.g. stemming, normalization and stop word removal, and to select word weighting schemes, it is in general quite hard to beat simple bag-of-words baselines in many cases.
However, it is widely observed that purely lexical features lead to brittle NLP systems that are easily overfit to particular domains. Furthermore, in certain text types such as social media, the brittleness is particularly acute due to the very wide variation in style, vocabulary, and spelling. Twitter texts, for instance, are notorious in this respect due to their short format. Problems of variation of style and spelling is also an issue in other nonstandard text types such as historical texts. In NLP systems that process these types of texts, it may be necessary to combine lexical features with more abstract back-off features that generalize beyond the surface strings in order to achieve a higher degree of robustness, and learning methods may need to be adjusted in order to learn models with more redundancy.
A number of issues are problematic for annotation of Old Swedish texts. For example, sentence splitting cannot be handled with standard tools, as sentence boundaries are often not marked by punctuation or uppercase letters. Compared to modern Swedish texts, the Old Swedish texts have a different vocabulary and richer morphology, show a divergent word order, and Latin and German influences. Finally, the lack of a standardized orthography results in a wide variety of spellings for the same word.
Question answering based on large and noisy knowledge sources
With the advent of massive online encyclopedic corpora such as Wikipedia, it has become possible to apply a systematic analysis to a wide range of documents covering a significant part of human knowledge. Using semantic parsers or related techniques, it has become possible to extract such knowledge in the form of propositions (predicate–argument structures) and build large proposition databases from these documents. Christensen et al. (2010) showed that using a semantic parser in information extraction can yield a higher precision and recall in areas where shallow syntactic approaches have failed. This deeper analysis can be applied to discover temporal and location-based propositions from documents. McCord et al. (2012) describe how the syntactic and semantic parsing components of the IBM Watson question answering system are applied to the text content and the questions to find answers and Fan et al. (2012) show how access to a large amount of knowledge was critical for its success.
Question answering systems are notable applications of semantic processing. They reached a milestone in 2011 when IBM Watson outperformed all its human co-contestants in the Jeopardy! quiz show (Ferrucci et al., 2010; Ferrucci, 2012). Watson answers questions in any domain posed in natural language using knowledge extracted from Wikipedia and other textual sources, encyclopedias, dictionaries such as WordNet, as well as databases such as DBPedia, and Yago (Fan et al., 2012). A goal of the project which will ensure its visibility is to replicate the IBM Watson system for Swedish with knowledge extracted from different sources such as the newspaper corpora stored in Språkbanken, the classical Swedish literary works available in Litteraturbanken, etc.
Tracking semantic change
When interpreting the content of historical documents, knowledge of changed word senses play an important role. Without knowing that the meaning of a word has changed we might falsely place a more current meaning on the word and thus interpret the text wrongly. As an example, the phrase an awesome concert should be interpreted as a positive phrase today. However, an awesome leader in a text written some hundred years ago, should be interpreted as a negative phrase only. The interpretation of awesome depends on the time of writing and not on the context terms concert or leader and is thus not a disambiguation problem. Instead, we consider this to be a manifestation of word sense change and present a method for automatically detecting such change. Our method utilizes automatically extracted word senses, by means of word sense induction, to find word sense changes given a collection of text. Our objective is to test the hypothesis that automatically derived word senses and the temporal comparison of these has the potential to capture changes in a word’s senses. We use unsupervised methods that require no manual input and show the potential of our method on a set of terms that have experienced change in the past centuries and consider it a proof-of-concept for our hypothesis. We present a novel method that is able to capture 95% of all senses and changes for modern English text over the past 200 years. We correctly detect and differentiate between different types of changes for 82% of all change events in our testset. We measure the time between an expected change in word sense and the corresponding found change to investigate not only if but when changes can be found and with which time delay.
Moving to Swedish content, we make use of a Swedish historical news corpus, the Kubhist dataset (Språkbanken), a OCRed newspaper corpus containing a varying degree of noise. As a comparison, initial experiments on Kubhist show that the maximum amount of induced clusters found one year is much smaller and thus makes it harder for us to detect word sense change. For the Swedish experiments, just like for the English experiments, the number of clusters strongly correlate (Pearson correlation of 0.9) with the amount of sentences in each yearly set. The Kubhist data is preprocessed with the Korp annotation pipeline (Borin, Forsberg and Roxendal (2012)) and not corrected for OCR error and hence the results are not directly comparable, but indicate the quality and quantity needs for methods relying on grammatical relations, at least when exact matching is considered for patterns like (N/NP) (and/or/,) (N/NP). Our initial experiments with distributional models on the Kubhist data, where each year has a maximum of 1.3M and an average of 5.2M sentences, show that also here a large amount of data is needed, in particular for methods that aim to create vectors for each sense of a word (e.g., Nieto Piña and Johansson (2015)) rather than for all senses at the same time, as is the case with e.g., Word2Vec (Mikolov, Chen, Corrado and Dean (2013)). Continuing our work on Swedish texts, we are evaluating different kinds of word sense induction algorithms, graph, topic as well as vector based models on the Swedish Culturomics Gigaword Corpus (Eide, Tahmasebi, Borin (2016)) to determine the best way to move forward.
Core NLP technologies
Finally, the project will develop or adapt Swedish NLP tools to support the research areas described above. Such tools can include named entity recognizers and disambiguators, coreference solvers, syntactic parsers, and semantic role labelers.
