


Ord kan förändra sina betydelser. Man behöver inte en doktorgrad i språkvetenskap för att upptäcka att grym i (1) betyder inte samma sak som i (2).
(1) -- Ja, så här grym kan fotbollen vara. Tyvärr, menade Gefles tränare Lennart 'Liston' Söderberg. Dagens Nyheter 1987-05-18
(2) Jag hörde inte vad mina lagspelare sa, om de kallade på mig eller minsta lilla, för det var en sådan skön och grym stämning. Svenska Dagbladet 2013-09-03
Det finns dock en del svårare frågor. Finns det några universella tendenser i betydelseförändring? Kan man förklara förändringen eller, ännu bättre, förutsäga den? Historisk semantik har jobbat länge med sådana frågor, men fram till nyss var de flesta undersökningar baserade på manuell kvalitativ analys av fåtal exempel. I det här inlägget berättar jag om ett enkelt, men effektivt sätt att göra kvantitativa undersökningar av betydelseförändringar. Då jag undervisade i semantik vid Uppsala universitet i 2018--2019, använde mina studenter den här metoden för självständiga miniforskningsprojekt.
För att göra kvantitativ språkforskning behöver man oftast en korpus (en stor elektronisk samling av texter, berikad med olika slags nyttig information). I det här exemplet ska vi använda två korpusar (en äldre och en nyare): en korpus av artiklar från Kalmars dagstidning på 1910-talet (en del av Kubhist-korpusen), och en korpus av inlägg på diskussionsforumet Flashback (underforum Dator & IT). Visst är det bäst att välja två mer jämförbara korpusar (t.ex. två tidningskorpusar), men som exempel duger det här paret.
Sedan väljer man ett (eller flera) ord man vill undersöka (vi kan fortsätta med grym) och söker efter ordet i de två korpusarna medelst Språkbankens Korp (Kalmar, Flashback). Sedan bestämmer man hur mycket tid man har för manuell analys och hur många exempel man vill gå igenorm (t.ex. 75 i varje korpus). Det är bekvämt att ladda ner träffsidan (se bilden) och jobba vidare i ett räkneblad. Exempel förekommer i en slumpmässig ordning, alltså det går bra att ta de första 75 exemplen som ett slumpmässigt urval.
För varje exempel noterar man vilken betydelse ordet grym har i just den här kontexten. Man ska ha en begränsad lista av möjliga betydelser (t.ex. använda listan från Svensk ordbok och utvida den vid behov).
När man är färdig, har man två frekvensfördelningar (som speglar ordets betydelse kring 1910 och kring 2010). Här är frekvensfördelningarna mina studenter fick i 2019.
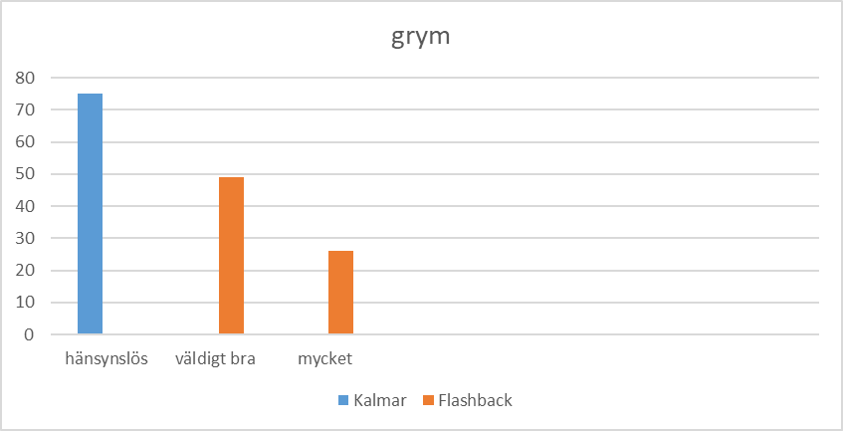
JS = 1
Det är möjligt att jämföra fördelningarna och även mäta hur olika de är, alltså mäta förändringsgraden. Ett passande mått är så kallad Jensen-Shannon divergens (JS). För ordet grym är JS lik med 1 (maximum), eftersom fördelningarna är helt olika, det finns ingen överlapp. I Kalmar betyder grym aldrig 'väldigt bra' eller 'mycket', och i Flashback betyder det aldrig 'hansynslös'.
Ett sådant öde (en negativ konkret betydelse, som i grym fiende >> en mer neutral allmän intensifierare, som i grymt snyggt >> en positiv allmän betydelse, som i fin och grym stämning) är ganska typiskt för ord med negativa konnotationer.
Låt oss titta på resultat studenterna fick för andra ord.
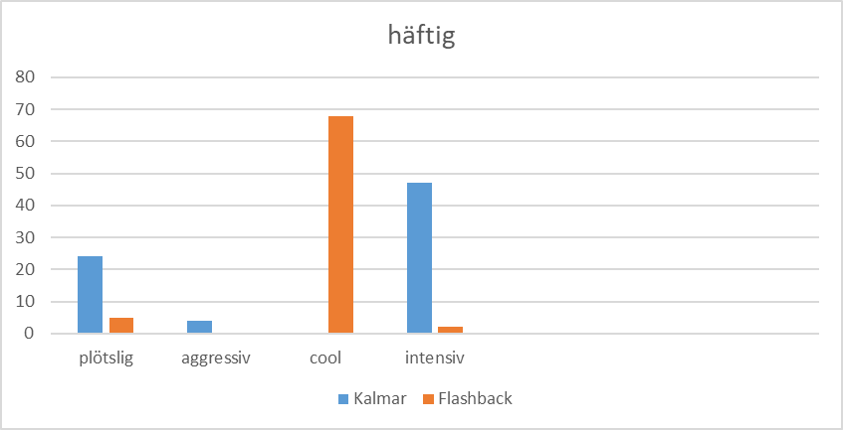
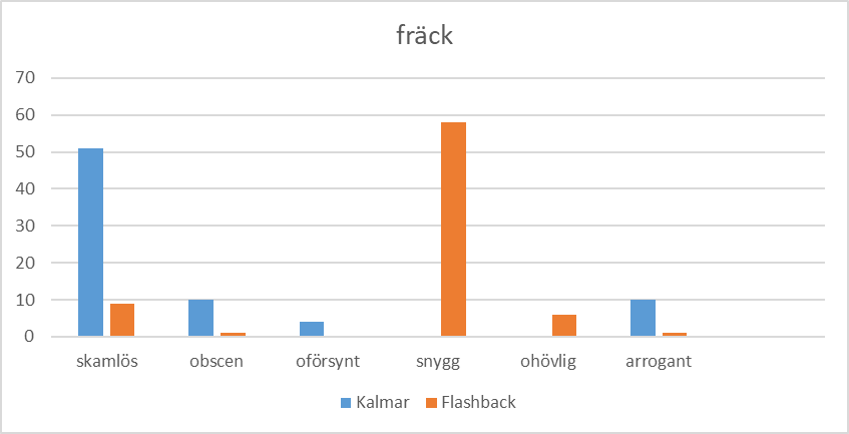
Både häftig och fräck går också från negativa till positiva konnotationer, fast inte på exakt samma sätt som grym. Ordet dryg tar dock en annan väg.
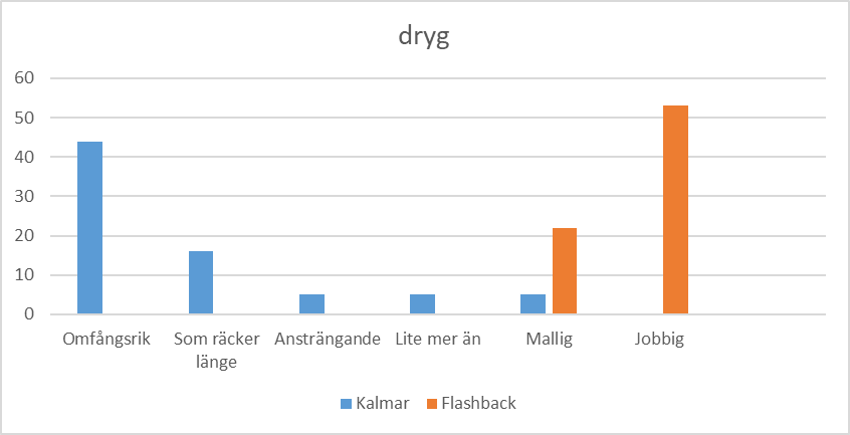
Här verkar förändringen gå från 'omfångsrik' till 'mallig' och sedan till 'jobbig', som är den dominerande betydelsen i Flashback.
Sist och slutligen låt oss titta på ordet skön där studenterna upptäckte en mindre synlig förändring (notera också att JS är mindre än i de andra exemplen).
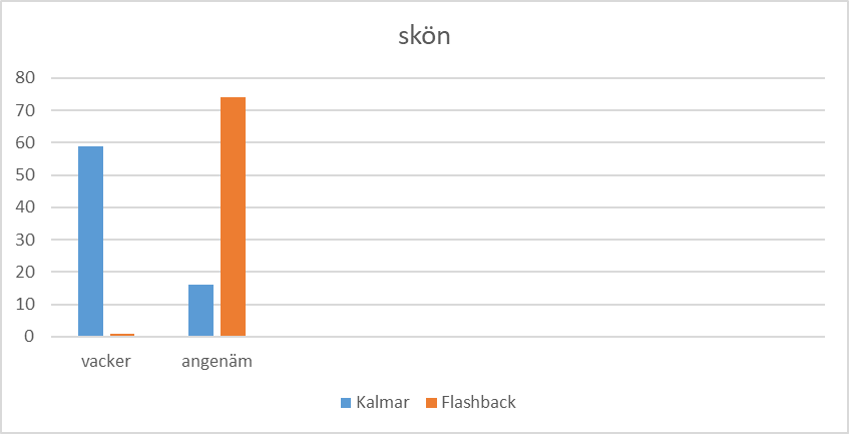
Den här enkla metoden passar utmärkt i undervisningen, men kan också tillämpas i forskning, fast då ska man, som sagt, välja mer jämförbara korpusar; jobba noggrant med analysen av betydelser och gå igenom fler kontexter.
Metoden kräver dock mycket manuellt arbete, och det innebär att det är möjligt att analysera bara ett begränsat antal kontexter. Vill man undvika den här restriktionen, måste man använda automatisk semantisk analys i stället. Datorer är inte så grymt bra som människor på att analysera mening, men forskare på Språkbanken håller på att utveckla metoder som möjliggör automatisk analys av betydelseförändringar.