

Zipfs lag, uppkallad efter den amerikanske lingvisten George Kingsley Zipf, säger att ett ords frekvens är omvänt proportionellt mot dess plats i en frekvenslista. Vad innebär det?
Låt oss tänka oss att vi gör en lista över de vanligaste orden i ett språk. På engelska ser vi då kanske att de vanligaste orden är:
| 1 | the |
| 2 | be |
| 3 | to |
| 4 | of |
| 5 | and |
Zipfs lag säger då att till exempel "be", på plats nummer 2, borde vara hälften så vanligt som "the"; "to" borde vara tre gånger mindre vanligt, och så vidare. Så om till exempel ett ord av 10 är "the", kan vi vänta oss att ett av 20 är "be", ett av 30 är "to", ett av 40 är "of"...
Det är förstås inte en exakt regel – man ska inte tro att det kommer stämma exakt för varje ord. Dessutom är det viktigt att komma ihåg att det inte finns bara en sanning när det gäller vilka ord som är vanligast, utan det beror på sammanhanget. Ord som "jag" eller "jaså" är förstås vanligare i talspråk, medan ord som "emellertid" och "utropade" antagligen är vanligare i böcker.
Men oavsett vilken typ av text man utgår från brukar regeln stämma ganska bra för de flesta ord. Studier har visat att den också fungerar på många olika språk. På Wikipedia hittar vi till exempel den här grafen, som visar sambandet för 30 olika språk:
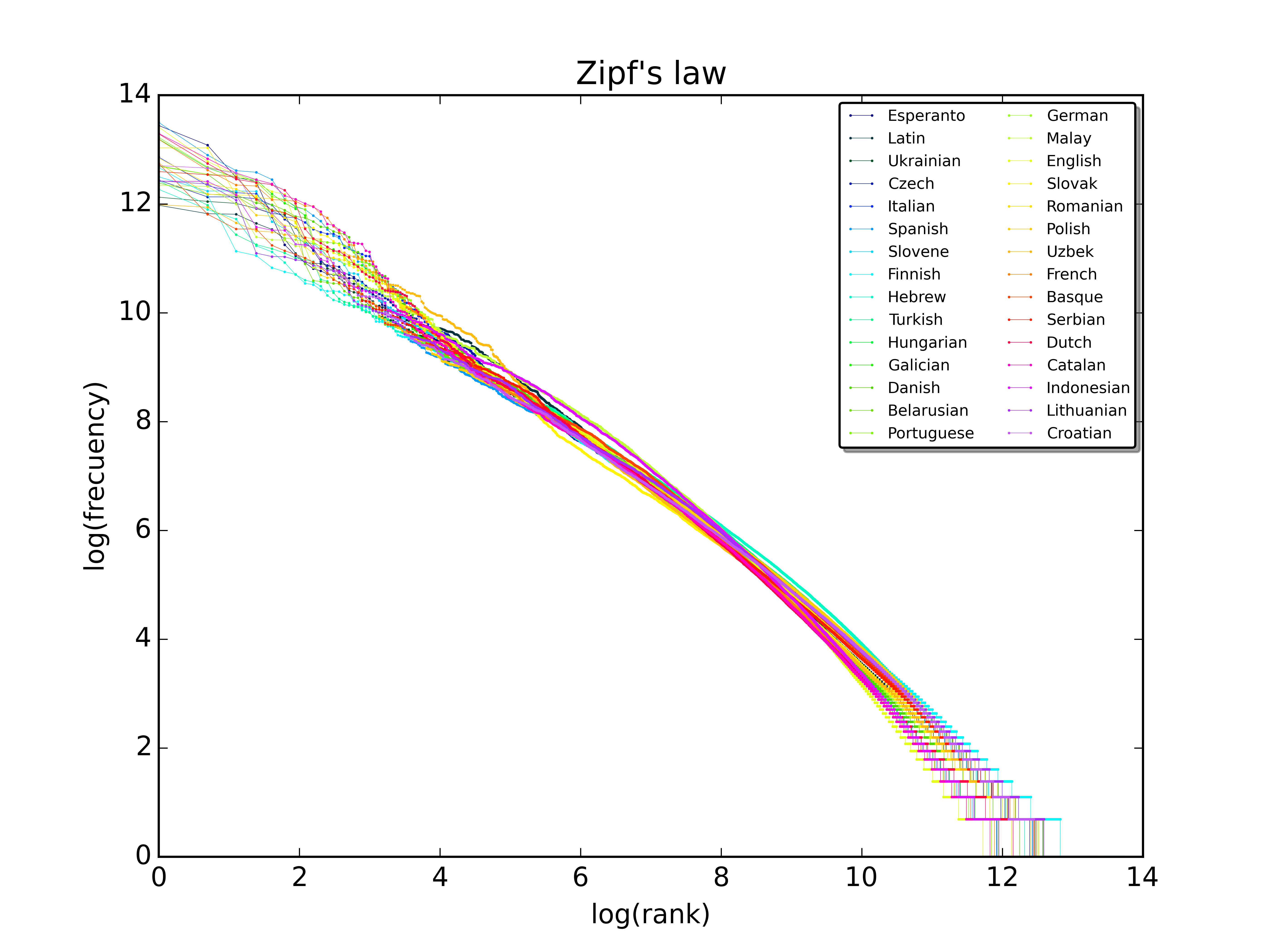
Men svenska är inte med i just den här grafen. Vi fick en fråga till Språkbanken för ett tag sen om ifall Zipfs lag gäller även för svenska. Så hur är det egentligen?
Jo, det kan vi lätt räkna ut genom att göra statistik på några av Språkbankens korpusar. Om vi utgår från hela samlingen av korpusar för modern svenska, kommer vi fram till att de vanligaste orden är:
| 1 | . (punkt) | 41‰ |
| 2 | , (komma) | 26‰ |
| 3 | och | 18‰ |
| 4 | är | 17‰ |
| 5 | det | 15‰ |
| 6 | i | 14‰ |
| 7 | jag | 12‰ |
| 8 | på | 12‰ |
| 9 | att | 12‰ |
| 10 | inte | 11‰ |
För det första kan man notera att vi räknar punkt, komma, och andra interpunktionstecken som "ord", även om de inte är riktigt som vanliga ord. Om vi sen tittar på hur vanliga orden är, ser vi till exempel att 18 promille, alltså 18 av 1000 ord, är "och", och så vidare.
Än så länge verkar det inte stämma särskilt bra med Zipfs lag. Ord nummer 10 är bara knappt 4 gånger så ovanligt som ord nummer 1. Men som sagt, vi ska inte förvänta oss att det stämmer exakt för varje ord. Låt oss titta lite längre ner på listan.
| 5 | det | 15‰ |
| 50 | nu | 2.2‰ |
| 500 | läsa | 0.18‰ |
| 5000 | fordon | 0.015‰ = 15 per miljon |
| 50 000 | IVA | 0.82 per miljon |
| 500 000 | Hasselbaink | 0.029 per miljon |
Exakt hur vanligt ordet "Hasselbaink" är varierar säkert en hel del mellan olika texter, men överlag ser det ut som att regeln kommer ganska nära. Vi kan också rita en graf på samma sätt som vi såg för de andra språken:

Precis som i de andra språken följer kurvan linjen ganska bra, men är lite nedåtböjd i början. Det är förstås inte oväntat att en regel som fungerar på så många andra språk också fungerar på svenska.
Har du också frågor till Språkbanken? Skicka dem till sb-info@gu.se!